| DPOGS200047 | ||
|---|---|---|
| Transcript | DPOGS200047-TA | 897 bp |
| Protein | DPOGS200047-PA | 298 aa |
| Genomic position | DPSCF300365 + 57565-59797 | |
| RNAseq coverage | 99x (Rank: top 61%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL007370 | 1e-84 | 59.69% | |
| Bombyx | BGIBMGA013988-TA | 2e-109 | 59.11% | |
| Drosophila | CG5731-PA | 2e-67 | 40.98% | |
| EBI UniRef50 | UniRef50_B7PDZ5 | 1e-69 | 38.15% | Alpha-D-galactosidase, putative n=3 Tax=Arthropoda RepID=B7PDZ5_IXOSC |
| NCBI RefSeq | NP_001040191.1 | 3e-72 | 43.85% | alpha-N-acetylgalactosaminidase [Bombyx mori] |
| NCBI nr blastp | gi|307213390 | 6e-72 | 41.25% | Alpha-N-acetylgalactosaminidase [Harpegnathos saltator] |
| NCBI nr blastx | gi|189238968 | 2e-72 | 43.92% | PREDICTED: similar to AGAP005846-PA [Tribolium castaneum] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0008152 | 1.6e-53 | metabolic process | |
| GO:0003824 | 1.6e-53 | catalytic activity | ||
| GO:0004553 | 6.3e-28 | hydrolase activity, hydrolyzing O-glycosyl compounds | ||
| GO:0005975 | 6.3e-28 | carbohydrate metabolic process | ||
| KEGG pathway | aag:AaeL_AAEL005188 | 8e-71 | ||
| K01189 (GLA) | maps-> | Galactose metabolism | ||
| Lysosome | ||||
| Glycerolipid metabolism | ||||
| Sphingolipid metabolism | ||||
| Glycosphingolipid biosynthesis - globo series | ||||
| InterPro domain | [18-278] IPR017853 | 1.1e-73 | Glycoside hydrolase, superfamily | |
| [17-161] IPR013785 | 1.6e-53 | Aldolase-type TIM barrel | ||
| [20-39] IPR002241 | 6.3e-28 | Glycoside hydrolase, family 27 | ||
| [51-132] IPR000111 | 1.7e-15 | Glycoside hydrolase, clan GH-D | ||
| Orthology group | MCL26158 | Lepidoptera specific | ||
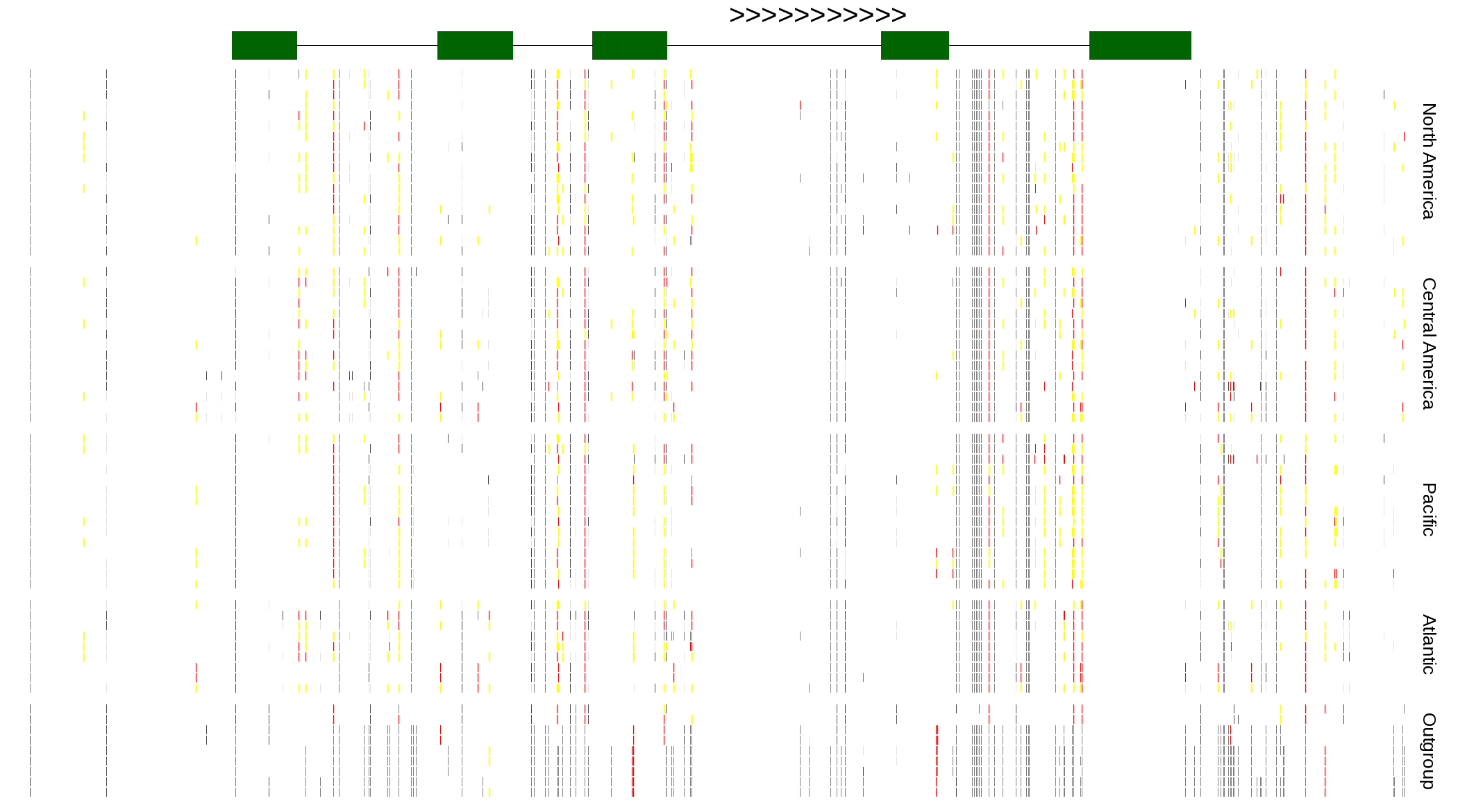
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS200047-TA
ATGTATCTCTGTTTATTTTTATTTATTGTTTATTTATGTGGTGTGAATTTATTAAATAACGGCCTGGCACAGAAGCCTCCCATGGGCTGGATGTCATGGGGATACTATATGTGTGGTGTGGACTGTAAAAGGAATCCTCATAAGTGTCTTAATGAGGAATTAATACTATCAGTGGTTGACTCGTTTTACGATGAAGGGTATCAGGAAGCTGGGTACGAATATATCATTATTGATGATTGCTGGTCGGAGAGAATACGTGATAAAAATGGTCGTCTCGTACCAGACAGGACAAGGTTTCCGAGAGGCATGAAATTTATCGCTGATTATATACATGCTAGAGGTCTTAAATTTGGATTGTACACTAATGTAGCGGACACCACATGTATGGGTTATCCCGGTTCAAGAGATCATTTCGCCATCGACGCCAAACAGTTTGCGCAGTGGGAAATAGATTATCTTAAAGTCGATGGTTGTTTTGTCAGCGAAGAATATCTTAATATTGATTATAAAAGTGTGGCTGAATATTGCAACATGTGGCGGAATTACCACGATGTGGCTACATCATGGGAGGCAGTTAAGGCCATTATAACACACTATCAAGGGGTATATAACGATATTAATGGTTATCACGGACCAGGCCATTGGAATGATCCAGATATGTTAATATTTGGAACTAATTCGCTGTCGGAGAGTCAGAGCAGAGTACAAATATCAGTATACTCAATGCTTGCCGCACCGTTGTTGTTAAGCTGTGACATGAAAAATATTAATGATTACGAGAAACAGATGTTACTTAATTTAGATCTAATAGCGATAGGTGTTCTGCTAGACCCCTATTACCGACGGCCTTACGCGGTATGTCCTCAAGCATATACTGACTTCAGGATAGGAGGTTAA
>DPOGS200047-PA
MYLCLFLFIVYLCGVNLLNNGLAQKPPMGWMSWGYYMCGVDCKRNPHKCLNEELILSVVDSFYDEGYQEAGYEYIIIDDCWSERIRDKNGRLVPDRTRFPRGMKFIADYIHARGLKFGLYTNVADTTCMGYPGSRDHFAIDAKQFAQWEIDYLKVDGCFVSEEYLNIDYKSVAEYCNMWRNYHDVATSWEAVKAIITHYQGVYNDINGYHGPGHWNDPDMLIFGTNSLSESQSRVQISVYSMLAAPLLLSCDMKNINDYEKQMLLNLDLIAIGVLLDPYYRRPYAVCPQAYTDFRIGG-