| DPOGS200469 | ||
|---|---|---|
| Transcript | DPOGS200469-TA | 2592 bp |
| Protein | DPOGS200469-PA | 863 aa |
| Genomic position | DPSCF300260 + 302718-305934 | |
| RNAseq coverage | 304x (Rank: top 37%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL010414 | 0.0 | 75.46% | |
| Bombyx | BGIBMGA011180-TA | 0.0 | 72.95% | |
| Drosophila | gammaCop-PB | 0.0 | 54.12% | |
| EBI UniRef50 | UniRef50_Q9Y678 | 0.0 | 52.00% | Coatomer subunit gamma n=161 Tax=Eukaryota RepID=COPG_HUMAN |
| NCBI RefSeq | NP_001036846.1 | 0.0 | 66.47% | nonclathrin coat protein gamma1-COP [Bombyx mori] |
| NCBI nr blastp | gi|7637410 | 0.0 | 73.09% | nonclathrin coat protein gamma2-COP [Bombyx mori] |
| NCBI nr blastx | gi|7637410 | 0.0 | 73.17% | nonclathrin coat protein gamma2-COP [Bombyx mori] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0005488 | 7.6e-107 | binding | |
| GO:0006886 | 2.9e-102 | intracellular protein transport | ||
| GO:0030117 | 2.9e-102 | membrane coat | ||
| GO:0016192 | 2.9e-102 | vesicle-mediated transport | ||
| GO:0005798 | 1.1e-61 | Golgi-associated vesicle | ||
| GO:0005198 | 1.1e-61 | structural molecule activity | ||
| GO:0030126 | 5.6e-43 | COPI vesicle coat | ||
| KEGG pathway | ||||
| InterPro domain | [5-863] IPR017106 | 0 | Coatomer, gamma subunit | |
| [19-584] IPR011989 | 7.6e-107 | Armadillo-like helical | ||
| [25-537] IPR002553 | 2.9e-102 | Clathrin/coatomer adaptor, adaptin-like, N-terminal | ||
| [1-579] IPR016024 | 1.4e-88 | Armadillo-type fold | ||
| [603-862] IPR014863 | 1.1e-61 | Coatomer, gamma subunit , appendage | ||
| [593-754] IPR013041 | 2.5e-47 | Clathrin/coatomer adaptor, adaptin-like, appendage, Ig-like subdomain | ||
| [596-750] IPR013040 | 5.6e-43 | Coatomer, gamma subunit, appendage, Ig-like subdomain | ||
| [756-862] IPR009028 | 6e-16 | Clathrin/coatomer adaptor, adaptin-like, appendage, C-terminal subdomain | ||
| [753-863] IPR015873 | 2.7e-10 | Clathrin alpha-adaptin/coatomer adaptor, appendage, C-terminal subdomain | ||
| Orthology group | MCL11188 | Multiple-copy universal gene | ||
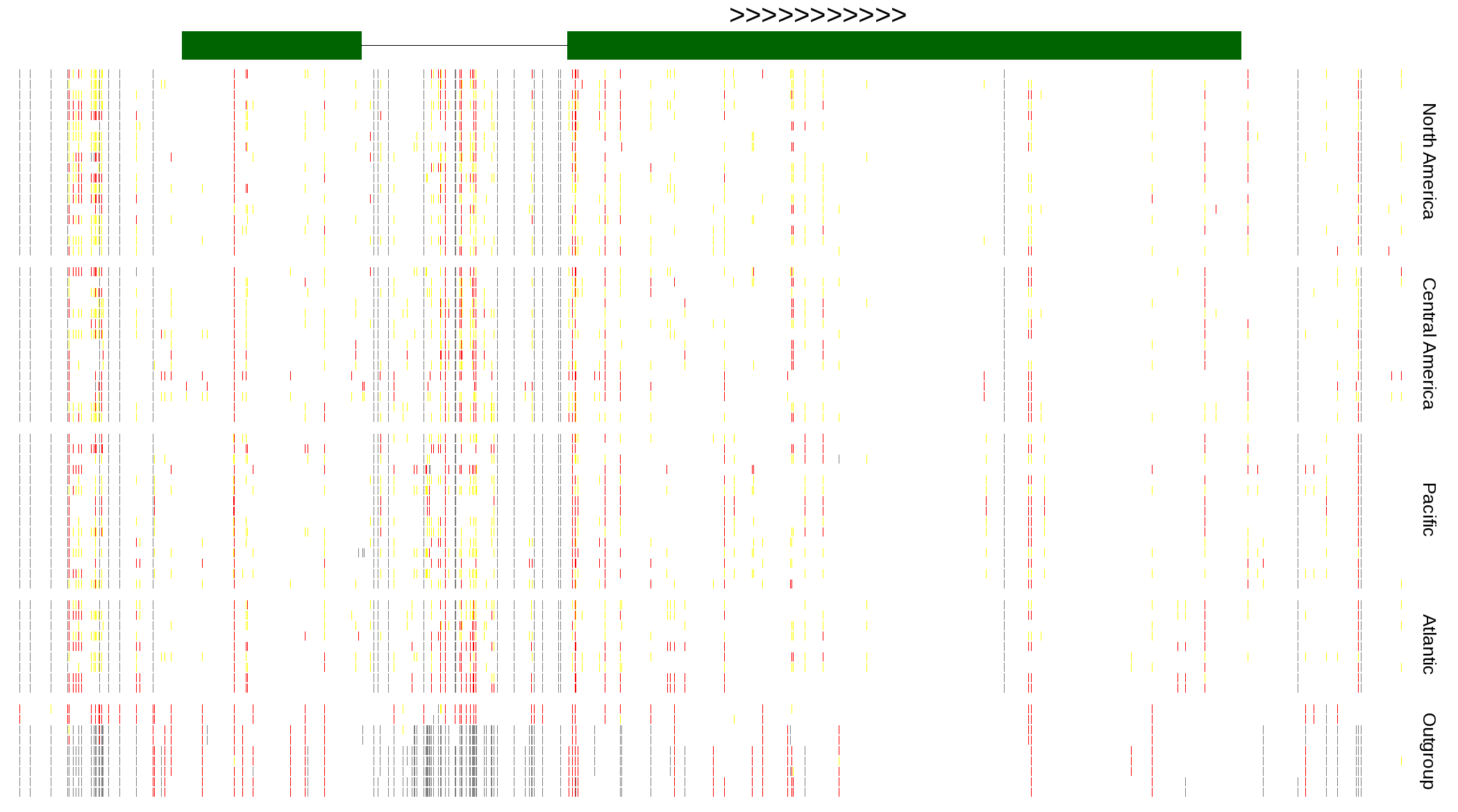
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS200469-TA
ATGAGCTCCTTTAAGCGTGATAAGAAGGAAGAAGAAGAGGGTGGGTGTTTTTCATTCCAGAACTTAGATAAAACCATCGTTTTGCAAGAATCGAGATATTTCAACGAGACGCCGGTGAACCCTCGGAAATGTACACAAATTCTAACGAAAATACTATTTCTGCTCAACCAAGGAGAGACATTCTCCACTCAGGAAGCTACAGAGGCTTTCTTCGCCATCACGAAGCTTTTCCAATCCAATGATGTTATTTTGCGGCGTATGGTGTATCTTTGCATCAAGGAATTGAGCAAACTGGCTCAGGATGTGATTATAGTTACATCTTCCTTAACCAAAGACATGACGGGCAAGGAGGATCTGTATAGGGCTGCGGCTATCCGAGCGCTGTGCAGTGTCACCGATAGCACCATGATTCAAGCTATTGAAAGATACATGAAGCAAGCTATCGTTGATAGAAACCCCGCGGTCAGTTCTGCGGCTCTGGTGTCGTCTTTGCATCTATCATCTACTTCACCGGATCTGGTGAAGCGATGGACGAGCGAGGCACAGGAAGCGTTGAACAGCGAAAAGTCACTCGTCTCGTACCATGCACTCGGAATACTTGTGAATATTCGTAGAACTGACAAGCTGTCAACCATGAAGCTAGTGACACGTCTCACCAAATCCTCAATAAAATCACCATACACTCTGTGCTTATTGATTCGTCTCGCTGCTCAACTAGTTGAAGATGATGCTTCGGAGACATCCCAAGCTTACATCGAGTTCATTGATGGCTGTCTCCGGCACAAATCAGAAATGGTGATTTATGAAGCTGCTCACGCGATTGTCAACTTGCGTAAAACAACACGAGATTTAGCTCCGGCTGTGTCAGTGCTACAGCTGTTCTGTGGTTCCTCCAAAGCGACCTTGAGACTCGCTGGAGCTAGAACCCTCGCCAAACTGACGACTAAACATCCAGCTGCAGTATCAGCCTGCACCATCGACCTGGAAAATCTGATCTCCGATCCAAACAGATCAGTTGCTACGCTGGCAGTCACGACTCTGCTGGCTACAGGCGCTGAGAGCTCCATCGATCGTCTCATGAAGCAGATCTCTAGCTTCGTTTCGGAGATATCGGACGAGTTTAAAATTATCGTAGTCAAGGCTATCAAACGCCTGTGCCTCAAGTTTCCTAGGAAGCACCAATCGTTGGCTACATTTTTGGCCGGCATGCTCCGCGATGAAGGTGGTTTAGATTATAAAGCGGCCATTGCTGACGCGATCATCGCTCTGGTGGAAGAAAACCCCGATGCCAAAGAGACAGGACTGGCTCATCTGTGCGAATTTATCGAAGATTGCGAGCACCAAGTCCTGTCGGTTCGGATTTTGCATTTATTGGGACGCGAAGGCCCTAAAACTCGCCATCCCACGAGATACATCAGATTCATCTACAATAGGGTCATCCTGGAGACGGGGCCGGTCAGGGCGGCTGCGGTCTCTGCTGTGGCGCAGTTCGGAGCCCACATTCCTGAACTCCTGCCAAATATAAGAGTTCTGTTAAGTCGCTGTGAAACCGACGAGGAAGATGAAGTGAGGGATCGCGCGATCTTCTTCAACGCGATCTTCAATTCGGGCAACGAGAAATTGATAAGAGATTATATCACCCACGTACCGAGAGTGAACCCGGTTCTGTTGGAAAAAGCCCTCCATGATCATGCCAAGAACAGGCCGAACGAACCCTTCGACATCCTGAGCGTCCCGGAGATGGAAAAACCGAAGAGAGAAGAAGTGGTAGAGATCGATGTGAAGCAACCGAAACAGATAACAATCGAGGAGATTTACAGCCAGCAGCTCGCGAAAATACCGGGCATCGAGAAATTGGGGACTATTTTCAAAACCAATAATCCGGTCGAACTCACGGAAGAGGACACAGAGTTCCAAGTCCGTCTGATTAAACACATCTACGTTCGTCACGTCGTCCTGCAGTTTGAATGCACGAGCACTATCAACTTCCATGTCTTCGAGAATGTGACCGTAAAATTGGATCTGCCCAACGAGTTCGAAGTGAAGAACATGGTGCCCATCAAGTCGTTGGCTTTCAACAGACCCGAGAGCATTTTTGTAATCGTGGAATTCCCCTGCTCGTTTCTGGACAGCATGAACCCCTTCGGTGCCATCCTGGAGTTTGTGACACGCGAATGTCACCCAATCACTTGTATGCCAAACCCCGGCCCAGGGTACATAGACACTTATCCTATCGAGGACTTCTACATCAGCTGCGCCGATCAAATACGCACGCGAGTCACCGGCGATGACTGGGAGCAGACTTGGGAGAGCGCTTTCAACGTCATCGAGATTTCAGATACTTTCTCTCTCCCTCAGCGAGACGCTGCGGCCGCTGCTAAGTCGGTTTGCGAATATCTCGGTCTACCGAAAGGTTCCATCACCGGGGACACGGTTAAGGAGATAAGGGGGGCCGGTATTTTTAGGGGCGGAGCGCCTTTCTTGGTCAGGGCTCGCATAGCGCCGACGAGCGCTGGAACTGCTACTATGCTGATCGCAGCACGATCTCCGAGAGAAGACGTGGCACAACTACTACTCAACGCTGTAGGTTAA
>DPOGS200469-PA
MSSFKRDKKEEEEGGCFSFQNLDKTIVLQESRYFNETPVNPRKCTQILTKILFLLNQGETFSTQEATEAFFAITKLFQSNDVILRRMVYLCIKELSKLAQDVIIVTSSLTKDMTGKEDLYRAAAIRALCSVTDSTMIQAIERYMKQAIVDRNPAVSSAALVSSLHLSSTSPDLVKRWTSEAQEALNSEKSLVSYHALGILVNIRRTDKLSTMKLVTRLTKSSIKSPYTLCLLIRLAAQLVEDDASETSQAYIEFIDGCLRHKSEMVIYEAAHAIVNLRKTTRDLAPAVSVLQLFCGSSKATLRLAGARTLAKLTTKHPAAVSACTIDLENLISDPNRSVATLAVTTLLATGAESSIDRLMKQISSFVSEISDEFKIIVVKAIKRLCLKFPRKHQSLATFLAGMLRDEGGLDYKAAIADAIIALVEENPDAKETGLAHLCEFIEDCEHQVLSVRILHLLGREGPKTRHPTRYIRFIYNRVILETGPVRAAAVSAVAQFGAHIPELLPNIRVLLSRCETDEEDEVRDRAIFFNAIFNSGNEKLIRDYITHVPRVNPVLLEKALHDHAKNRPNEPFDILSVPEMEKPKREEVVEIDVKQPKQITIEEIYSQQLAKIPGIEKLGTIFKTNNPVELTEEDTEFQVRLIKHIYVRHVVLQFECTSTINFHVFENVTVKLDLPNEFEVKNMVPIKSLAFNRPESIFVIVEFPCSFLDSMNPFGAILEFVTRECHPITCMPNPGPGYIDTYPIEDFYISCADQIRTRVTGDDWEQTWESAFNVIEISDTFSLPQRDAAAAAKSVCEYLGLPKGSITGDTVKEIRGAGIFRGGAPFLVRARIAPTSAGTATMLIAARSPREDVAQLLLNAVG-