| DPOGS200490 | ||
|---|---|---|
| Transcript | DPOGS200490-TA | 996 bp |
| Protein | DPOGS200490-PA | 331 aa |
| Genomic position | DPSCF300158 - 50937-52300 | |
| RNAseq coverage | 2956x (Rank: top 4%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL008268 | 7e-175 | 91.24% | |
| Bombyx | BGIBMGA010423-TA | 5e-172 | 90.63% | |
| Drosophila | Mdh1-PA | 2e-136 | 74.16% | |
| EBI UniRef50 | UniRef50_P40925 | 1e-124 | 66.26% | Malate dehydrogenase, cytoplasmic n=84 Tax=root RepID=MDHC_HUMAN |
| NCBI RefSeq | NP_001040257.1 | 4e-171 | 90.94% | cytosolic malate dehydrogenase [Bombyx mori] |
| NCBI nr blastp | gi|114052561 | 8e-170 | 90.94% | cytosolic malate dehydrogenase [Bombyx mori] |
| NCBI nr blastx | gi|114052561 | 2e-168 | 90.94% | cytosolic malate dehydrogenase [Bombyx mori] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0055114 | 9.6e-222 | oxidation-reduction process | |
| GO:0006108 | 9.6e-222 | malate metabolic process | ||
| GO:0016615 | 9.6e-222 | malate dehydrogenase activity | ||
| GO:0030060 | 1.6e-162 | L-malate dehydrogenase activity | ||
| GO:0016616 | 3.2e-81 | oxidoreductase activity, acting on the CH-OH group of donors, NAD or NADP as acceptor | ||
| GO:0003824 | 3.2e-81 | catalytic activity | ||
| GO:0005975 | 3.2e-81 | carbohydrate metabolic process | ||
| GO:0005488 | 6.3e-71 | binding | ||
| GO:0044262 | 1.4e-68 | cellular carbohydrate metabolic process | ||
| GO:0016491 | 1.5e-36 | oxidoreductase activity | ||
| KEGG pathway | aag:AaeL_AAEL007707 | 8e-138 | ||
| K00025 (MDH1) | maps-> | Citrate cycle (TCA cycle) | ||
| Pyruvate metabolism | ||||
| Proximal tubule bicarbonate reclamation | ||||
| Carbon fixation in photosynthetic organisms | ||||
| Glyoxylate and dicarboxylate metabolism | ||||
| InterPro domain | [1-326] IPR010945 | 9.6e-222 | Malate dehydrogenase, type 2 | |
| [6-326] IPR011274 | 1.6e-162 | Malate dehydrogenase, NAD-dependent, cytosolic | ||
| [155-329] IPR015955 | 3.2e-81 | Lactate dehydrogenase/glycoside hydrolase, family 4, C-terminal | ||
| [1-154] IPR016040 | 6.3e-71 | NAD(P)-binding domain | ||
| [4-326] IPR001557 | 1.4e-68 | L-lactate/malate dehydrogenase | ||
| [156-327] IPR022383 | 4.8e-44 | Lactate/malate dehydrogenase, C-terminal | ||
| [5-153] IPR001236 | 1.5e-36 | Lactate/malate dehydrogenase, N-terminal | ||
| Orthology group | MCL15150 | Single-copy universal gene | ||
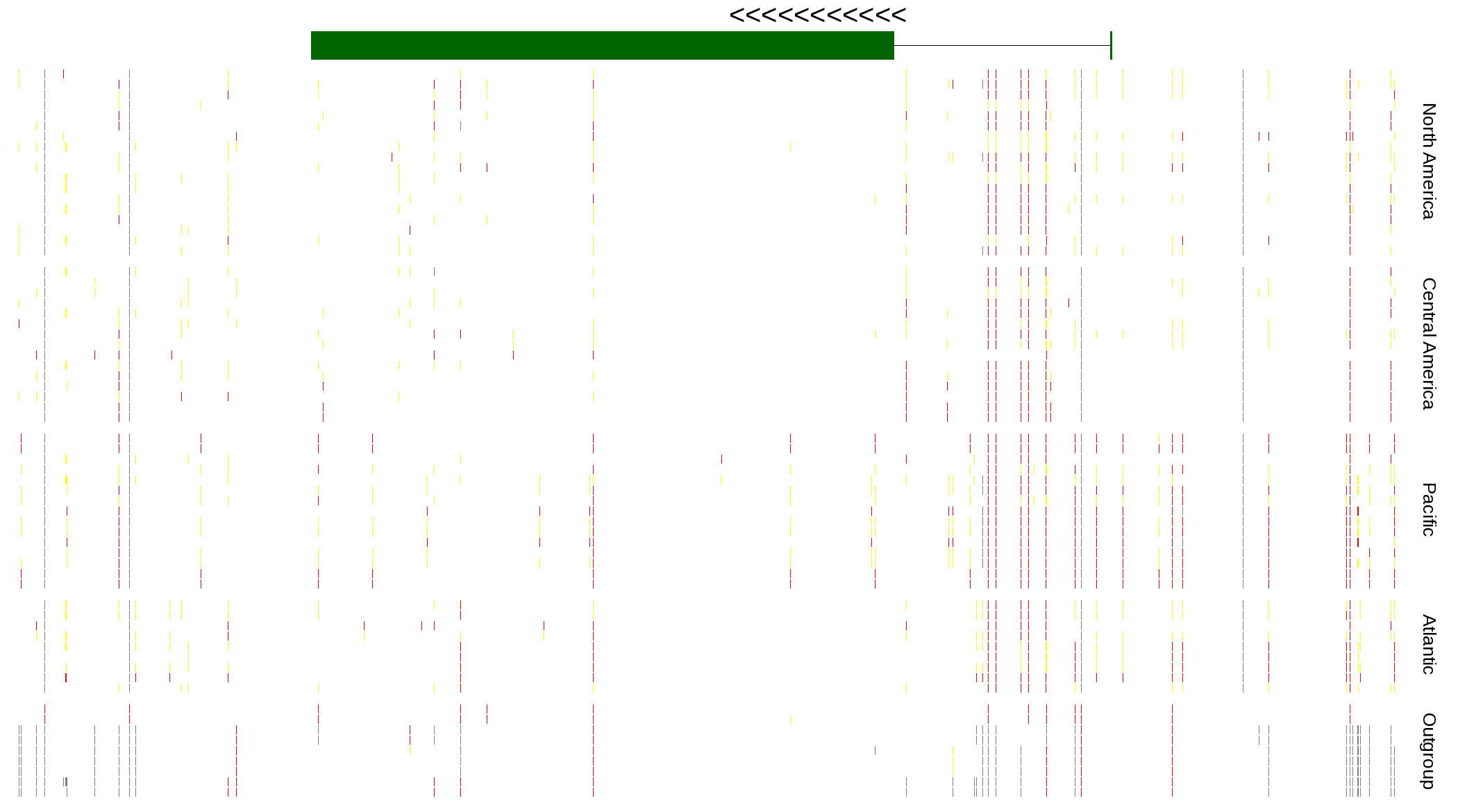
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS200490-TA
ATGGCTGCACCAATCAAAGTTGTTGTAACAGGGGCTGCTGGTCAAATCGCGTACTCTCTTCTATACCAAGTTGCTTCTGGAGCGGTTTTTGGTCCAGAACAACCTGTATTCCTGCACCTTCTTGATATTGCTCCCATGATGGGAGTGCTGGAAGGTGTTGTTATGGAACTTGCTGACTGCGCTCTACCTTTATTAGCTGGTGTTTTACCCACTGCCAATCCTGAAGAAGCATTTAAGGATGTAGCTGCTGCTTTTCTAGTTGGTGCTATGCCAAGAAGGGAAGGAATGGAAAGAAAAGACCTTCTTTCTGCTAATGTACGCATTTTCAAAGAACAAGGTCAAGCTTTGGATAAAGTTGCTCGCAAGGATGTCAAAGTTCTTGTTGTTGGCAACCCTGCTAATACAAATGCTTTGATCTGTTCTAAATATGCCCCATCTATTCCAAAAGAGAATTTCACTGCTATGACTCGTCTTGATCAGAATCGTGCCCAGTCTCAATTAGCAGCTAAGCTTGGAGTACCAGTACAGGATGTTAAGAATGTTATTATCTGGGGTAACCATTCATCCACTCAATTCCCTGATGCCTCCAATGCGAAAGTCAGAATTGGTGGTGTTGAAAAATCTGTGCCGGAAGCTATAAACAATGATGCTTTCTTAAAAACTGATTTTGTATCCACTGTACAAAAGCGCGGTGCAGCTGTTATAGCAGCTAGAAAGATGTCATCAGCTTTGTCAGCGGCCAAGGCAGCTTCTGATCACATGAGAGATTGGTTCTTGGGAACTGGCGATCGTTGGGTCAGTATGGGAGTTGTGTCTGATGGTTCTTACGGTGTTCCCAAAGACGTTGTTTATTCCTTCCCCGTCACTGTCTCTAATGGAAAATGGAAAATTGTTGAGGGTCTTACAATCTCTGATTTTGCACGGGAAAAATTAGATATCACTGGAAAGGAACTAGTTGAAGAGAAACAGGATGCTTTGGATGTGTGCAAAGATTAA
>DPOGS200490-PA
MAAPIKVVVTGAAGQIAYSLLYQVASGAVFGPEQPVFLHLLDIAPMMGVLEGVVMELADCALPLLAGVLPTANPEEAFKDVAAAFLVGAMPRREGMERKDLLSANVRIFKEQGQALDKVARKDVKVLVVGNPANTNALICSKYAPSIPKENFTAMTRLDQNRAQSQLAAKLGVPVQDVKNVIIWGNHSSTQFPDASNAKVRIGGVEKSVPEAINNDAFLKTDFVSTVQKRGAAVIAARKMSSALSAAKAASDHMRDWFLGTGDRWVSMGVVSDGSYGVPKDVVYSFPVTVSNGKWKIVEGLTISDFAREKLDITGKELVEEKQDALDVCKD-