| DPOGS200745 | ||
|---|---|---|
| Transcript | DPOGS200745-TA | 3240 bp |
| Protein | DPOGS200745-PA | 1079 aa |
| Genomic position | DPSCF300030 + 241641-252614 | |
| RNAseq coverage | 606x (Rank: top 21%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL010085 | 0.0 | 89.88% | |
| Bombyx | BGIBMGA001042-TA | 0.0 | 79.16% | |
| Drosophila | CG33298-PB | 0.0 | 52.86% | |
| EBI UniRef50 | UniRef50_Q7PMF8 | 0.0 | 50.35% | AGAP010026-PA n=4 Tax=Culicidae RepID=Q7PMF8_ANOGA |
| NCBI RefSeq | XP_968357.2 | 0.0 | 52.75% | PREDICTED: similar to AGAP010026-PA [Tribolium castaneum] |
| NCBI nr blastp | gi|189236367 | 0.0 | 52.75% | PREDICTED: similar to AGAP010026-PA [Tribolium castaneum] |
| NCBI nr blastx | gi|270005885 | 0.0 | 51.89% | hypothetical protein TcasGA2_TC008001 [Tribolium castaneum] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0000287 | 4e-168 | magnesium ion binding | |
| GO:0005524 | 4e-168 | ATP binding | ||
| GO:0015914 | 4e-168 | phospholipid transport | ||
| GO:0016021 | 4e-168 | integral to membrane | ||
| GO:0004012 | 4e-168 | phospholipid-translocating ATPase activity | ||
| GO:0016020 | 8.2e-31 | membrane | ||
| GO:0015662 | 8.2e-31 | ATPase activity, coupled to transmembrane movement of ions, phosphorylative mechanism | ||
| GO:0006754 | 8.2e-31 | ATP biosynthetic process | ||
| GO:0046872 | 2.7e-16 | metal ion binding | ||
| GO:0000166 | 2.7e-16 | nucleotide binding | ||
| GO:0016820 | 5.3e-13 | hydrolase activity, acting on acid anhydrides, catalyzing transmembrane movement of substances | ||
| KEGG pathway | ||||
| InterPro domain | [450-1030] IPR006539 | 4e-168 | ATPase, P-type, phospholipid-translocating, flippase | |
| [729-813] IPR023214 | 2.8e-49 | HAD-like domain | ||
| [453-618] IPR023299 | 2.2e-32 | ATPase, P-type, cytoplasmic domain N | ||
| [729-842] IPR001757 | 8.2e-31 | ATPase, P-type, K/Mg/Cd/Cu/Zn/Na/Ca/Na/H-transporter | ||
| [111-153] IPR023300 | 4.1e-23 | ATPase, P-type, cytoplasmic transduction domain A | ||
| [17-249] IPR008250 | 2.7e-16 | ATPase, P-type, ATPase-associated domain | ||
| [457-620] IPR023306 | 5.3e-13 | ATPase, cation-transporting, domain N | ||
| Orthology group | MCL10945 | Multiple-copy universal gene | ||
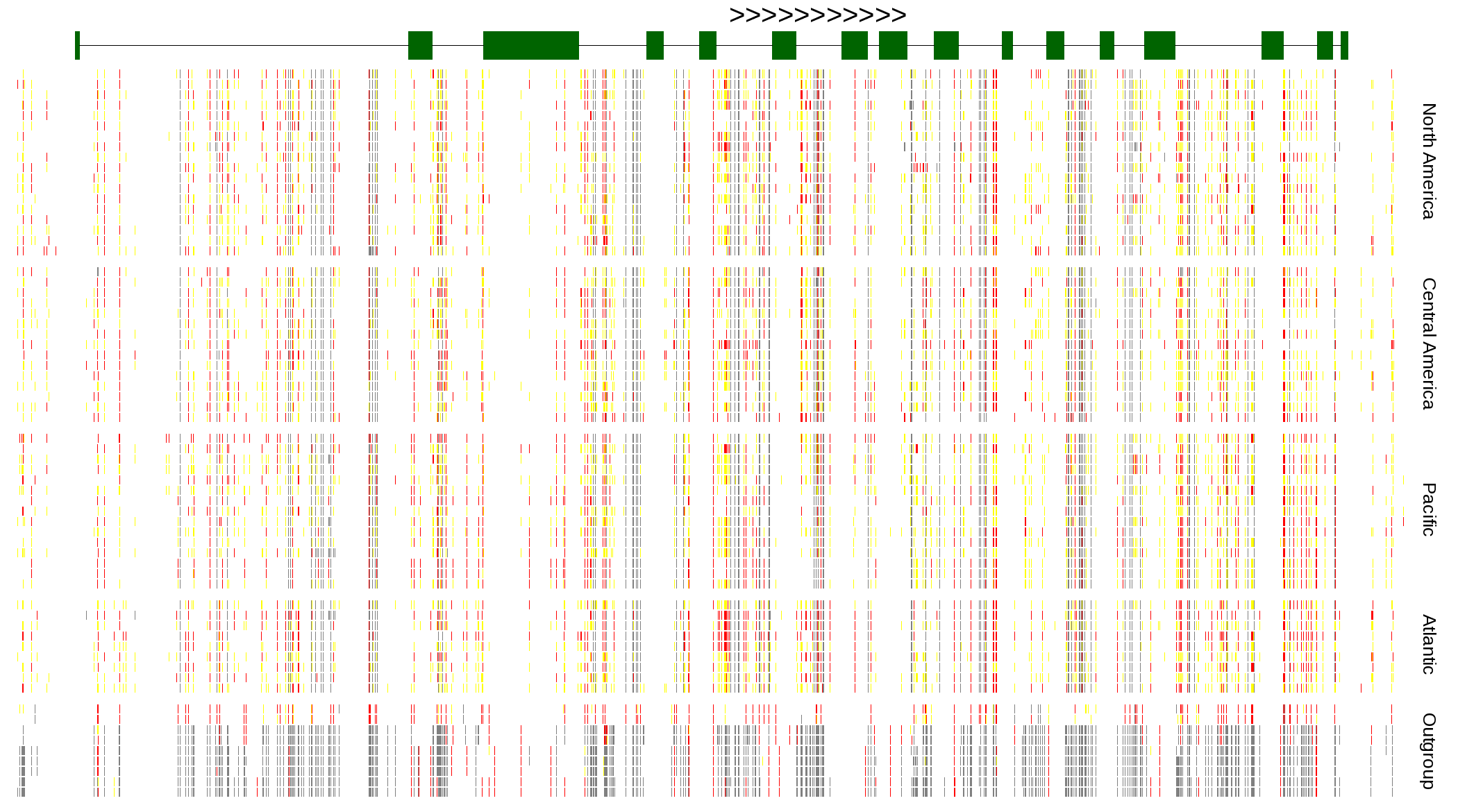
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS200745-TA
ATGAAACTCGAAGGTCGCGGTCTGACAGTGATTGGATCGGTTGAGAGATACGTTCGTGTCAAATGGCGGGATGTTCGAGTCGGAGACCTGGTTCATCTGTCCAACAACGAGGCAGTGCCAGCGGACATGGTCCTGCTGCACTCCTCGAACCAGTCAGGGCTGTGCTACCTTGACACCTGCAACCTGGACGGTGAAACGAATCTCAAACAACGTATGGTAGCTCCTGGGTTCAAAGACAAGCGATTGGAGTTTTCCCCTATGAAATTCCGTAGCTCCGTGGAGGTGGAGCGGCCGTCCACGAAGATTTATAGGTTCAACGGGACTATATCACACCCGGACGGTACTCGAGTTCCGCTAAACTCTGATAACCTCCTGCTGAGAGAATGCACAATCAAGAACACGGATTACATTGAAGGCATCGTCGTGTACGCGGGACATGAAACAAAGGCCATGCTCAACAACGGCGGGCCGAGATACAAATGTTCCAAGTTAGAGAAAAAAATGAATACCGATGTTATCTGGTGTGTTCTGGTGTTGCTGTTTCTCTGCTGTGCTGGTGCTGTTGGCTGTAAAGTGTGGTTGGACTTCTACAACCCAGCCGTCATGAAATACACGCCTTTCATACCGTACGCCGAGAAACCAGCTTACGAAGGCCTGCTGATATTTTGGACGTACATCATAGTCCTTCAAGTGATGATACCGGTGTCGCTATACGTTACTATAGAAATGACGAAGCTGTTGCAAGTCTACCACATACATCAGGACGTTGAGATGTATGATTCGGTTACAAACACGCGGACTGAGTGCCGGGCGTTGAACATAACGGAGGAGTTGGGGCAGGTCAGTTATTTGTTCAGCGACAAGACTGGCACCTTGACCGAGAATAAGATGGTCTTCAGGCGGTGTACGGTCGGCGGGGTTGACTACGACCATCCGCCCGGTCCAGATGCCGCGCCCTCCAGCTCCTTACCGCCCATCGTCACTCCGATAACAAAAGTCTCACCCAACAGAAGATTGCTTCAACATCTTCTAGACAGCAACGACCCTCAACATACGCATAAGGTCTCCGAGTTCCTCTTGATCCTGGCTGTTTGCAACACGGTGGTGGTGAGCCAGCCTCACGTGGACGCTATGCAGATGAGCACGAGCAGCGAGCACGTGCGCAAGCCGACGAGGAACGGAACGCTCCGATCAAACGATAAGTACGCTAGATTAACTGAATCTCGGTCCACAACGCCGTCCCCGCCGCCCTCCACCACCTCCCCGCTGCGTCTCCGCCTTCCCAAACTACCGTTCAGCAGTCGGGAAGACAGCATCAGCGAACCGAGCACGTCGGCTGAAATACAGCTGGCGCGTTTCGAGGCTGAGAGTCCGGATGAGTTGGCCTTAGCGGAGGCGGCCTTAGCCTACGGTTACGAGTTAAGAGGACGGTCGGTGGATGAAGTGGAGCTGGGGATACGAGGGGAACTGTCCAAGCTGAAGGTGGTCAGGGTCCAACAATTCGACTCCAACAGGAAATGTATGTCCGTCGCCCTGAGAACACCTACAGGACAGGTAGTTTTATACGTGAAAGGAGCGGATAGTATGGTGTTGGGAGCACTGGCGCCCATGAGAGCCGGATCTGCAGAAGCGGCCGCCTTGGAAAGAACCAAGTCGCTATTACTGGAATACTCACGAGCGGGTCTTCGCACACTGGTCATGGCAAAACGAACGATGCAACCCGCTCTGTGGGAGGAATGGCTGGCTGGACACACCAGGGCCAGCGAAATTGGCGAAGGTCGAGAAAAACGCATGCGAGAGTCGCTGGCAAGGTTAGAGAGCGCGCTAACCTTAGTAGGGGCGACGGGGGTCGAGGATCGTCTTCAGGAGGACGTTCCACGCACTGTTCGGGCGTTACTCGACGCTGGTATCGTGGTATGGGTTCTGACCGGAGACAAGCCGGAGACGGCCATCAACATAGCTTACTCAGCGGCGTTGTTCTCACAGAGCGACAGACTGCTGCATCTCATGTCGAGGGACAAGGAGCACGCCGAGTCCACTATCAAGAGTTACCTGGAGGGCGGCGCGGTGGAGGGCGGCGGTGGTCGCGCGCTGGTGGTGGACGGCCGCACCCTCACCTACATCCTCGACCGCCGCTCCGGCTTGGTGGCGCCCTTCCTCTCACTGGCCAGGCGCTGCTCCGCCGTACTCTGCTGTCGGGCCACGCCGCTACAGAAGGCTTATATCGTCAAGGCTGTTAAAGAAGAACTCGGAGTTACGACGCTAGCTATAGGGGACGGTGCCAATGATGTGTCTATGATTCAGACAGCCGATGTTGGTGTTGGTCTCTCAGGTCAGGAGGGCCGCCAGGCGGTGATGGCCTCGGACTTCGCCCTCCCCCGCTTCAAGTTCGTGGAGCGCCTGCTGCTCGTCCACGGTCATTGGTGTTACGACAGGCTCGCCAGGATGATACTCTACTTCTTCCTTAAGAACGCTACGTTCGTGTTCCTCGTGTTCTGGTACCAGTTGTACTGCGGCTACTCCTCGTCCGTGATGATCGACCAACTCCACCTCATGGCGTACAACCTCGCCTTCACAGCCTTCCCGCCCATAGTCATAGGTGCGTACGACCGCGTAGCTCCCAGCGGCCTGCTGTCGGAGCGGCCGGGGCTGTACAGCGCGTGTCGCCGCGGCCTGTCCTACAGGGCTCACTCGTACTGGCTGGTGTTGGCGGAGTCGGTGTACATCAGCGTCGTGATCTTCTTCACCGCCAAACAGGCCTACTGGGACTCGGACGTAGACCTCTGGCTGTTCGGCCTCTGTAACATGACCTGCTGCCTCGTCATCATGCTGGTGTACGTCGCCATAGAGACCAGGAGCTGGACTGTGATCCACCTGCTGGCCCTGACGGGTTCCCTGGGCTCGTTCTTCCTGCTGACCCTGGTCTACCAGACGGTGTGTGTTTCCTGCTTCAAGCTACCCTCCACATACTTCGTGATGCATCACGCCTTCGTCGACCCAGTCTACTGGCTGGTCGTCATCGTCACTACGGTGGCGGCGTTGGCGCCCAGATTAACATGGCACGCGATCCGTAACTCCGTTCGTCCGGGTGCTCTCGGGCGGGCCGTGCTCGCCAGGCGGCGGCGGGCCCGGCCGTACGCCGCACACTACCACACGCCCTCCGCCTCCGCACACGTTTACAGAGCCACGGACGAGGACGGGCTGCAGAAGACTCAGCCGGACGTGACGGCCATCACGTGA
>DPOGS200745-PA
MKLEGRGLTVIGSVERYVRVKWRDVRVGDLVHLSNNEAVPADMVLLHSSNQSGLCYLDTCNLDGETNLKQRMVAPGFKDKRLEFSPMKFRSSVEVERPSTKIYRFNGTISHPDGTRVPLNSDNLLLRECTIKNTDYIEGIVVYAGHETKAMLNNGGPRYKCSKLEKKMNTDVIWCVLVLLFLCCAGAVGCKVWLDFYNPAVMKYTPFIPYAEKPAYEGLLIFWTYIIVLQVMIPVSLYVTIEMTKLLQVYHIHQDVEMYDSVTNTRTECRALNITEELGQVSYLFSDKTGTLTENKMVFRRCTVGGVDYDHPPGPDAAPSSSLPPIVTPITKVSPNRRLLQHLLDSNDPQHTHKVSEFLLILAVCNTVVVSQPHVDAMQMSTSSEHVRKPTRNGTLRSNDKYARLTESRSTTPSPPPSTTSPLRLRLPKLPFSSREDSISEPSTSAEIQLARFEAESPDELALAEAALAYGYELRGRSVDEVELGIRGELSKLKVVRVQQFDSNRKCMSVALRTPTGQVVLYVKGADSMVLGALAPMRAGSAEAAALERTKSLLLEYSRAGLRTLVMAKRTMQPALWEEWLAGHTRASEIGEGREKRMRESLARLESALTLVGATGVEDRLQEDVPRTVRALLDAGIVVWVLTGDKPETAINIAYSAALFSQSDRLLHLMSRDKEHAESTIKSYLEGGAVEGGGGRALVVDGRTLTYILDRRSGLVAPFLSLARRCSAVLCCRATPLQKAYIVKAVKEELGVTTLAIGDGANDVSMIQTADVGVGLSGQEGRQAVMASDFALPRFKFVERLLLVHGHWCYDRLARMILYFFLKNATFVFLVFWYQLYCGYSSSVMIDQLHLMAYNLAFTAFPPIVIGAYDRVAPSGLLSERPGLYSACRRGLSYRAHSYWLVLAESVYISVVIFFTAKQAYWDSDVDLWLFGLCNMTCCLVIMLVYVAIETRSWTVIHLLALTGSLGSFFLLTLVYQTVCVSCFKLPSTYFVMHHAFVDPVYWLVVIVTTVAALAPRLTWHAIRNSVRPGALGRAVLARRRRARPYAAHYHTPSASAHVYRATDEDGLQKTQPDVTAIT-