| DPOGS201540 | ||
|---|---|---|
| Transcript | DPOGS201540-TA | 2319 bp |
| Protein | DPOGS201540-PA | 772 aa |
| Genomic position | DPSCF300006 + 1655741-1668530 | |
| RNAseq coverage | 931x (Rank: top 14%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL009067 | 0.0 | 87.21% | |
| Bombyx | BGIBMGA002716-TA | 0.0 | 83.02% | |
| Drosophila | CG5009-PA | 6e-154 | 54.30% | |
| EBI UniRef50 | UniRef50_Q7KML2 | 9e-152 | 54.30% | Probable peroxisomal acyl-coenzyme A oxidase 1 n=26 Tax=Neoptera RepID=ACOX1_DROME |
| NCBI RefSeq | XP_001847631.1 | 0.0 | 62.34% | acyl-CoA oxidase [Culex quinquefasciatus] |
| NCBI nr blastp | gi|332027665 | 0.0 | 64.99% | Putative peroxisomal acyl-coenzyme A oxidase 1 [Acromyrmex echinatior] |
| NCBI nr blastx | gi|332027665 | 0.0 | 64.99% | Putative peroxisomal acyl-coenzyme A oxidase 1 [Acromyrmex echinatior] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0003997 | 5.1e-270 | acyl-CoA oxidase activity | |
| GO:0006631 | 5.1e-270 | fatty acid metabolic process | ||
| GO:0050660 | 5.1e-270 | flavin adenine dinucleotide binding | ||
| GO:0005777 | 5.1e-270 | peroxisome | ||
| GO:0055114 | 5.1e-270 | oxidation-reduction process | ||
| GO:0016627 | 1.6e-54 | oxidoreductase activity, acting on the CH-CH group of donors | ||
| GO:0006635 | 3e-53 | fatty acid beta-oxidation | ||
| GO:0008152 | 2.9e-52 | metabolic process | ||
| GO:0003995 | 8.3e-44 | acyl-CoA dehydrogenase activity | ||
| KEGG pathway | cqu:CpipJ_CPIJ006187 | 1e-180 | ||
| K00232 (E1.3.3.6, ACOX1, ACOX3) | maps-> | Peroxisome | ||
| Fatty acid metabolism | ||||
| Biosynthesis of unsaturated fatty acids | ||||
| PPAR signaling pathway | ||||
| alpha-Linolenic acid metabolism | ||||
| InterPro domain | [1-772] IPR012258 | 5.1e-270 | Acyl-CoA oxidase | |
| [1-737] IPR023570 | 2.3e-203 | Acyl-CoA oxidase, peroxisomal | ||
| [397-559] IPR009075 | 1.6e-54 | Acyl-CoA dehydrogenase/oxidase C-terminal | ||
| [589-770] IPR002655 | 3e-53 | Acyl-CoA oxidase, C-terminal | ||
| [6-280] IPR009100 | 2.9e-52 | Acyl-CoA dehydrogenase/oxidase | ||
| [147-277] IPR006091 | 8.3e-44 | Acyl-CoA oxidase/dehydrogenase, central domain | ||
| [20-146] IPR013786 | 4.1e-31 | Acyl-CoA dehydrogenase/oxidase, N-terminal | ||
| Orthology group | MCL10144 | Multiple-copy universal gene | ||
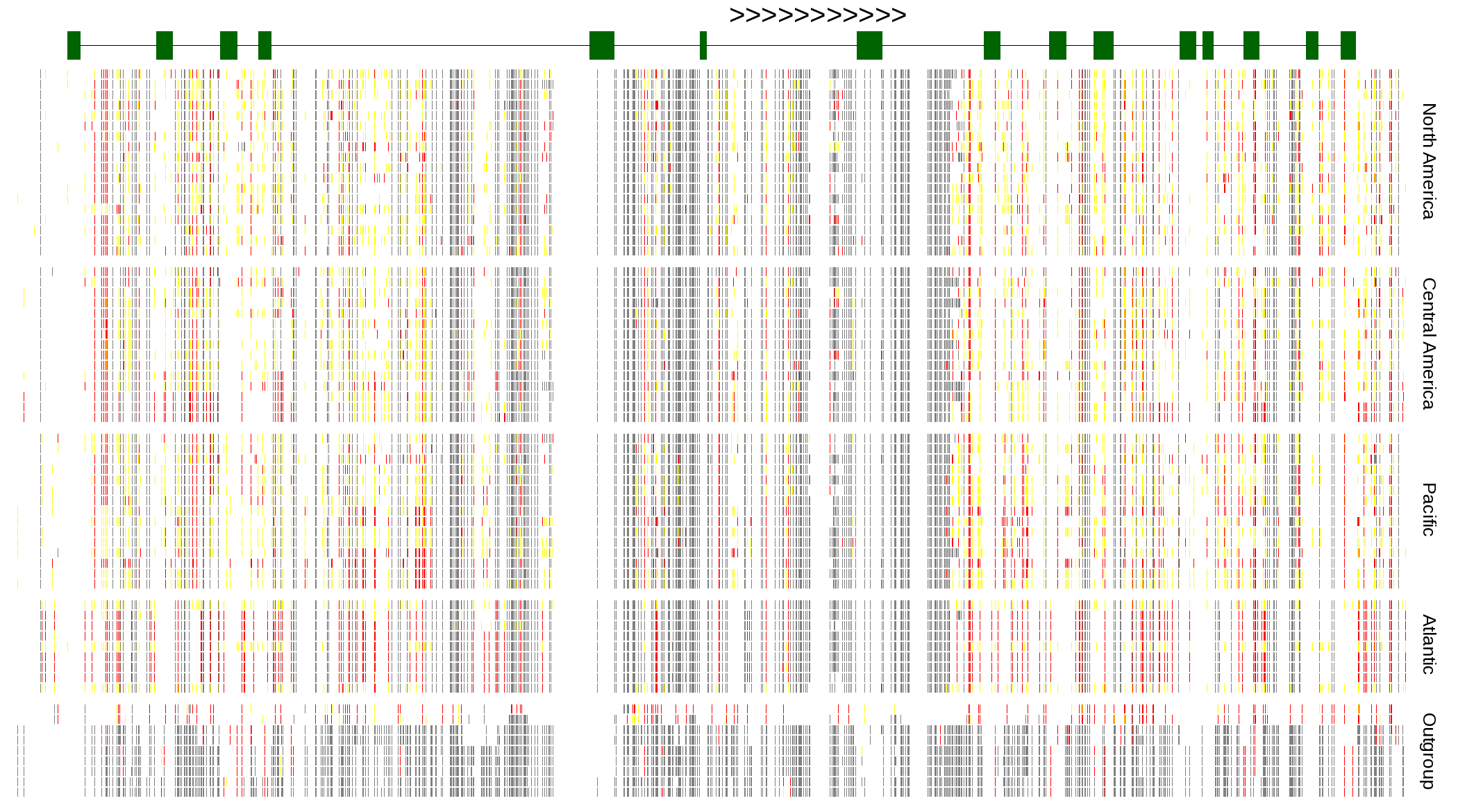
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS201540-TA
ATGGTGTCTAATAAAATAAACGCCGATTTACAAAAAGAAAGGGATTCTTGTAGTTTTAATGTCACCGAATTAACAAACTTAATTGATGGAGGTATTGAGAAAACTGCCGAAAGGAAGAAAAGAGAGGAAATGGCTCTCAAAGAAGGTATACATTTGGACGAAGTTCCGTCTGTGTATTTGAGTCACAAGGAGAAATATGAGTTAGCGATCAAGAAAGCCTGCCTCCTGTTTAAAATGATAAGACGACTTCAGGAAGAGGAAAATGCTGGCATGGAAAATTATATGGCAGTGCTTGGAGGTAATTTAGGGTCGGCCATTCTTGGGGATGGATCCCCTCTCACCCTCCACTATGTAATGTTCATACCCACATTGATGGGACAGGGTACAGTGGAACAGCAGGCTTATTGGATCGGCAGAGCATTTAATCTTGACATCATTGGCACATACGCTCAGACTGAATTGGGTCATGGCACATTCGTCCGCGGTCTTGAGACCACAGCCACCTACGATCCTTCTACTAAGGAGTTCATTCTACACAGCCCCACACTCACCGCATACAAGTGGTGGCCAGGCGGACTGGCCCACACAGCCAACTACTGTATAGTTATGGCCCAACTGCACACGAAAGGCAAATGCCACGGCATGCACGCCTTCATAGTCCAATTGCGTGATGAAGAAACACACATGCCCTTACCGGGGATTAAAGTTGGGGAGATCGGCGCCAAGCTCGGTATGAACGGCACTAACAACGGATTCCTTGGCTTCGACCAAGTCAGAATACCCAGAGACTATATGCTAATGAAGAACGCTAAAGTTTTAGAGAATGGACAGAAACTTTCAGCTGTACATCAGTATACCTTGGTGCATCATAGTGTCTTGANTAAATTGGCCCACACAGCCAACTACTGTATAGTTATGGCCCAACTGCACACGAAAGGCAAATGCCACGGCATGCACGCCTTCATAGTCCAATTGCGTGATGAAGAAACACACATGCCCTTACCGGGGATTAAAGTTGGTGAGATCGGCGCCAAGCTCGGTATGAACGGCACTAACAACGGATTCCTTGGCTTCGACCAAGTCAGAATACCCAGAGACTATATGCTAATGAAGAACGCTAAAGTTTTAGAGGACGGTACATACGTGACTGCACCAAGCTCGAAGCTCGCGTACGGCACCATGATGTTCGTGCGAGTGATGTTGGTCAACGACATGTGTAACTACATGGCTAAAGCGGTCACCATAGCCACCAGATACAGCGCTGTGAGGAGACAGTCGCAGCCTAAACCCAATGAACCGGAACCCCAGATCTTGGATTACGTGACGCAGCAGCACAAGTTGATGATAGGTCTAGCGTCGGTCCACGCCTTCAGAACATGCGCTGATTGGCTCTGGCAGATGTACAACAACGTCACCGCTGAACTCGAAGCGGGGGATATGGAGAGACTTCCAGAGCTTCACGCGTTATCGTGCTGTTTGAAAGCGGTGAGTACATCAGATGCCGCTCAGTGCGTGGAGCGCTGCAGACTGGCGTGCGGCGGACACGGGTACATGCTGTCCTCCAACTTGCCGCTCACATACGGTCTGGTCACGGCCGCCTGCACTTACGAAGGAGAGAATACCGTCATGTTGCTGCAGACTGCCAGATACCTGGTGAAGGCGTGGCAGCAGGCGGCCGGTGGCCAGACTCTACCACCGACGGTGAGTTACCTTCGCGAGGTGGTCGCCGGTCGTCGGTCGCCACCATTCGACAACACCATAGATGGTATAATCGCTGGCTTCTACCGAGTCGCCGCTGGTAAAATCGGTGCCTGTGTGGCGCAAATAGAGAAACGTCAGAAAACAGGCATGCCATACGAGGACGCCTGGAATATGACATCCGTTCAACTGACTTCAGCATCGGAGGCCCACTGTCGTGCGATAATCTTGTCAACGTACTACAAGGAGATCGAGCGTCAGAGTAACTCGGTTTCCCCCGAGCTGTCGACAGTGCTACGGCAGTTGGTAGACCTGTATGTGGTGTATTGGGCGCTGCAGTGCATTGGAGACCTACTCAGGTTCACATCGATCTCTGAGCGTGACATCGACCAACTTCAGGCCTGGTACGAGGATCTCCTCACCAGGCTTAGGCCGAACGCGGTGGGACTCGTGGACGCCTTCGACATTAGGGACGAGATCCTCAACTCTGCGCTGGGTGCATACGATGGCAATGCCTACGAACGTCTTATGGCGGAAGCTATGAAGAGCCCTCTCAACAAGGAACCGGTCAATCAAAGCTTCCATCAGTACTTGAAACCATTGATGCAGGGAAAGCTATAG
>DPOGS201540-PA
MVSNKINADLQKERDSCSFNVTELTNLIDGGIEKTAERKKREEMALKEGIHLDEVPSVYLSHKEKYELAIKKACLLFKMIRRLQEEENAGMENYMAVLGGNLGSAILGDGSPLTLHYVMFIPTLMGQGTVEQQAYWIGRAFNLDIIGTYAQTELGHGTFVRGLETTATYDPSTKEFILHSPTLTAYKWWPGGLAHTANYCIVMAQLHTKGKCHGMHAFIVQLRDEETHMPLPGIKVGEIGAKLGMNGTNNGFLGFDQVRIPRDYMLMKNAKVLENGQKLSAVHQYTLVHHSVLXKLAHTANYCIVMAQLHTKGKCHGMHAFIVQLRDEETHMPLPGIKVGEIGAKLGMNGTNNGFLGFDQVRIPRDYMLMKNAKVLEDGTYVTAPSSKLAYGTMMFVRVMLVNDMCNYMAKAVTIATRYSAVRRQSQPKPNEPEPQILDYVTQQHKLMIGLASVHAFRTCADWLWQMYNNVTAELEAGDMERLPELHALSCCLKAVSTSDAAQCVERCRLACGGHGYMLSSNLPLTYGLVTAACTYEGENTVMLLQTARYLVKAWQQAAGGQTLPPTVSYLREVVAGRRSPPFDNTIDGIIAGFYRVAAGKIGACVAQIEKRQKTGMPYEDAWNMTSVQLTSASEAHCRAIILSTYYKEIERQSNSVSPELSTVLRQLVDLYVVYWALQCIGDLLRFTSISERDIDQLQAWYEDLLTRLRPNAVGLVDAFDIRDEILNSALGAYDGNAYERLMAEAMKSPLNKEPVNQSFHQYLKPLMQGKL-