| DPOGS203543 | ||
|---|---|---|
| Transcript | DPOGS203543-TA | 1140 bp |
| Protein | DPOGS203543-PA | 379 aa |
| Genomic position | DPSCF300055 + 303979-307974 | |
| RNAseq coverage | 933x (Rank: top 14%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL013206 | 7e-91 | 98.76% | |
| Bombyx | BGIBMGA004344-TA | 0.0 | 90.26% | |
| Drosophila | G-salpha60A-PB | 0.0 | 84.68% | |
| EBI UniRef50 | UniRef50_P63092 | 6e-172 | 72.59% | Guanine nucleotide-binding protein G(s) subunit alpha isoforms short n=40 Tax=Euteleostomi RepID=GNAS2_HUMAN |
| NCBI RefSeq | NP_001093292.1 | 0.0 | 94.47% | G protein alpha S subunit Gs1 [Bombyx mori] |
| NCBI nr blastp | gi|153791974 | 0.0 | 94.47% | G protein alpha S subunit Gs1 [Bombyx mori] |
| NCBI nr blastx | gi|153791974 | 0.0 | 94.47% | G protein alpha S subunit Gs1 [Bombyx mori] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0007186 | 2.7e-271 | G-protein coupled receptor protein signaling pathway | |
| GO:0019001 | 2.7e-271 | guanyl nucleotide binding | ||
| GO:0004871 | 2.7e-271 | signal transducer activity | ||
| GO:0005525 | 5.7e-43 | GTP binding | ||
| GO:0007165 | 7.2e-43 | signal transduction | ||
| KEGG pathway | aga:AgaP_AGAP012095 | 0.0 | ||
| K04632 (GNAS) | maps-> | Salivary secretion | ||
| GnRH signaling pathway | ||||
| Amoebiasis | ||||
| Gap junction | ||||
| Vibrio cholerae infection | ||||
| Vasopressin-regulated water reabsorption | ||||
| Gastric acid secretion | ||||
| Dilated cardiomyopathy | ||||
| Vascular smooth muscle contraction | ||||
| Chagas disease | ||||
| Calcium signaling pathway | ||||
| Long-term depression | ||||
| Melanogenesis | ||||
| Taste transduction | ||||
| InterPro domain | [1-379] IPR001019 | 2.7e-271 | Guanine nucleotide binding protein (G-protein), alpha subunit | |
| [71-85] IPR000367 | 5.7e-43 | G-protein alpha subunit, group S | ||
| [47-180] IPR011025 | 7.2e-43 | G protein alpha subunit, helical insertion | ||
| Orthology group | MCL11808 | Single-copy universal gene | ||
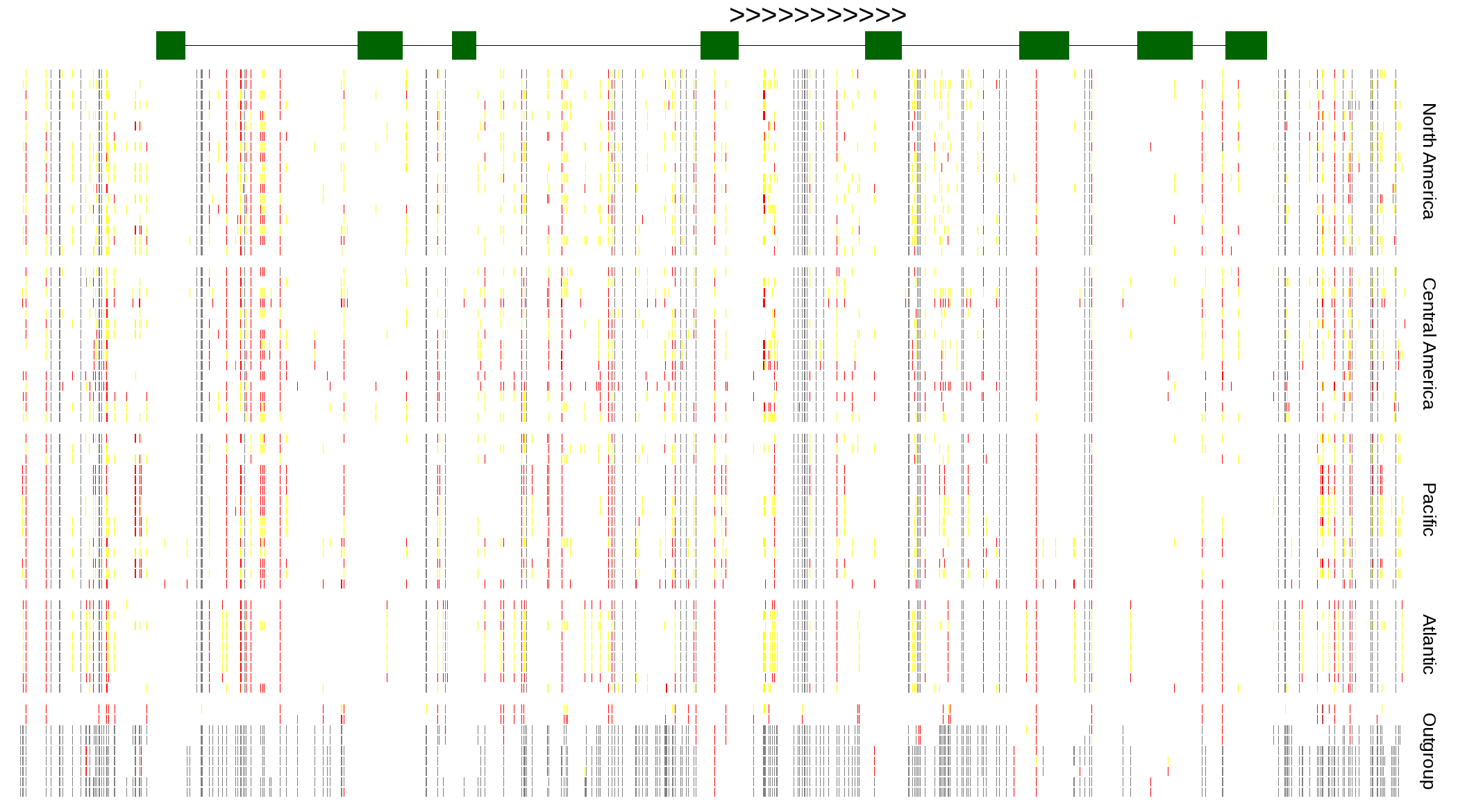
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS203543-TA
ATGGGGTGCTTCGGGTCACCGGGCGCCAAGAGTGGGGAGGATGACGCCAAGTCACAGAAACGCCGCAGCGACGCCATCACACGCCAGCTGCAGAAGGACAAGCAGCTGTACCGGGCAACCCACCGCCTGCTGCTCCTGGGGGCCGGTGAGTCCGGCAAGTCTACGATCGTGAAACAGATGCGTATACTCCACGTGAACGGCTTCTCGGATAAAGAGAGACGGGAGAAGATCGAAGATATTAAGAAAAACATACGTGATGCTATCCTTACAATAACTGGTGCTATGAGTACTCTGACACCTCCCATACCGCTTGAGAAGGTGGAGAACAAAGCTCGTGTTGATTACATCCAGGATGTCGCCTCGCAGCCTGACTTCGACTACCCTCCAGAGTTCTACGAGCATACGGAGGAGCTCTGGAAGGACCAGGGGGTGCAGAGGACCTACGAGAGGAGCAATGAGTACCAGCTCATAGACTGCGCCAAGTATTTCCTGGATCAGGTGCATATAATAAAGAGAGCTGACTACACGCCATCAGAGCAGGATATACTCCGCTGTCGAGTTCTCACCTCCGGGATATTCGAGACCCAGTTCGTCGTCGATAAAGTCAATTTTCATATGTTCGACGTGGGCGGGCAGCGTGACGAGCGCCGGAAGTGGATCCAGTGCTTCAACGATGTGACGGCCATCATCTTCGTGACCGCGTGCTCCTCATACAACATGGTGCTGAGAGAGGATCCCACACAGAACAGGCTCCGGGAGTCGCTGGACCTTTTCAAGAGCATATGGAATAACAGATGGCTCCGTACGATATCGGTGATCCTGTTCCTCAACAAGCAGGACCTGCTGGCTGAGAAGGTGTTGGCGGGGAAGTCTCGTCTCGAGGAGTACTTTGCGGAGTTCGCCCGCTACCAGACGCCGCCCGACGCGACCCCCGACACGAGGGACCACCCGGACGTCGCCAGGGCCAAGTACTTCATCAGAGATGAGTTCCTGCGCATCAGTACAGCGAGCGGTGACGGCAAGCACTACTGCTACCCTCACTTCACGTGCGCCGTCGACACTGAGAACATTAAGCGCGTCTTCAACGACTGCCGCGACATCATACAGCGCATGCACCTCAGACAGTACGAGCTGCTCTAA
>DPOGS203543-PA
MGCFGSPGAKSGEDDAKSQKRRSDAITRQLQKDKQLYRATHRLLLLGAGESGKSTIVKQMRILHVNGFSDKERREKIEDIKKNIRDAILTITGAMSTLTPPIPLEKVENKARVDYIQDVASQPDFDYPPEFYEHTEELWKDQGVQRTYERSNEYQLIDCAKYFLDQVHIIKRADYTPSEQDILRCRVLTSGIFETQFVVDKVNFHMFDVGGQRDERRKWIQCFNDVTAIIFVTACSSYNMVLREDPTQNRLRESLDLFKSIWNNRWLRTISVILFLNKQDLLAEKVLAGKSRLEEYFAEFARYQTPPDATPDTRDHPDVARAKYFIRDEFLRISTASGDGKHYCYPHFTCAVDTENIKRVFNDCRDIIQRMHLRQYELL-