| DPOGS204125 | ||
|---|---|---|
| Transcript | DPOGS204125-TA | 723 bp |
| Protein | DPOGS204125-PA | 240 aa |
| Genomic position | DPSCF300184 + 37316-38783 | |
| RNAseq coverage | 46x (Rank: top 71%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL011484 | 7e-92 | 69.74% | |
| Bombyx | BGIBMGA014557-TA | 1e-66 | 74.67% | |
| Drosophila | CG14507-PC | 3e-35 | 45.20% | |
| EBI UniRef50 | UniRef50_UPI00015B48C7 | 8e-47 | 58.78% | UPI00015B48C7 related cluster n=1 Tax=unknown RepID=UPI00015B48C7 |
| NCBI RefSeq | XP_001601787.1 | 2e-47 | 58.78% | PREDICTED: similar to ENSANGP00000018874 [Nasonia vitripennis] |
| NCBI nr blastp | gi|156540704 | 3e-46 | 58.78% | PREDICTED: hypothetical protein LOC100117598 [Nasonia vitripennis] |
| NCBI nr blastx | gi|156540704 | 4e-49 | 59.59% | PREDICTED: hypothetical protein LOC100117598 [Nasonia vitripennis] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0016042 | 4.6e-35 | lipid catabolic process | |
| GO:0005509 | 4.6e-35 | calcium ion binding | ||
| GO:0004623 | 4.6e-35 | phospholipase A2 activity | ||
| KEGG pathway | nvi:100117598 | 4e-47 | ||
| K01047 (PLA2G) | maps-> | GnRH signaling pathway | ||
| Fc epsilon RI signaling pathway | ||||
| MAPK signaling pathway | ||||
| Linoleic acid metabolism | ||||
| alpha-Linolenic acid metabolism | ||||
| Arachidonic acid metabolism | ||||
| Vascular smooth muscle contraction | ||||
| Glycerophospholipid metabolism | ||||
| Long-term depression | ||||
| Ether lipid metabolism | ||||
| VEGF signaling pathway | ||||
| InterPro domain | [104-216] IPR001211 | 4.6e-35 | Phospholipase A2, eukaryotic | |
| [108-239] IPR016090 | 5.5e-28 | Phospholipase A2 | ||
| Orthology group | MCL12340 | Multiple-copy universal gene | ||
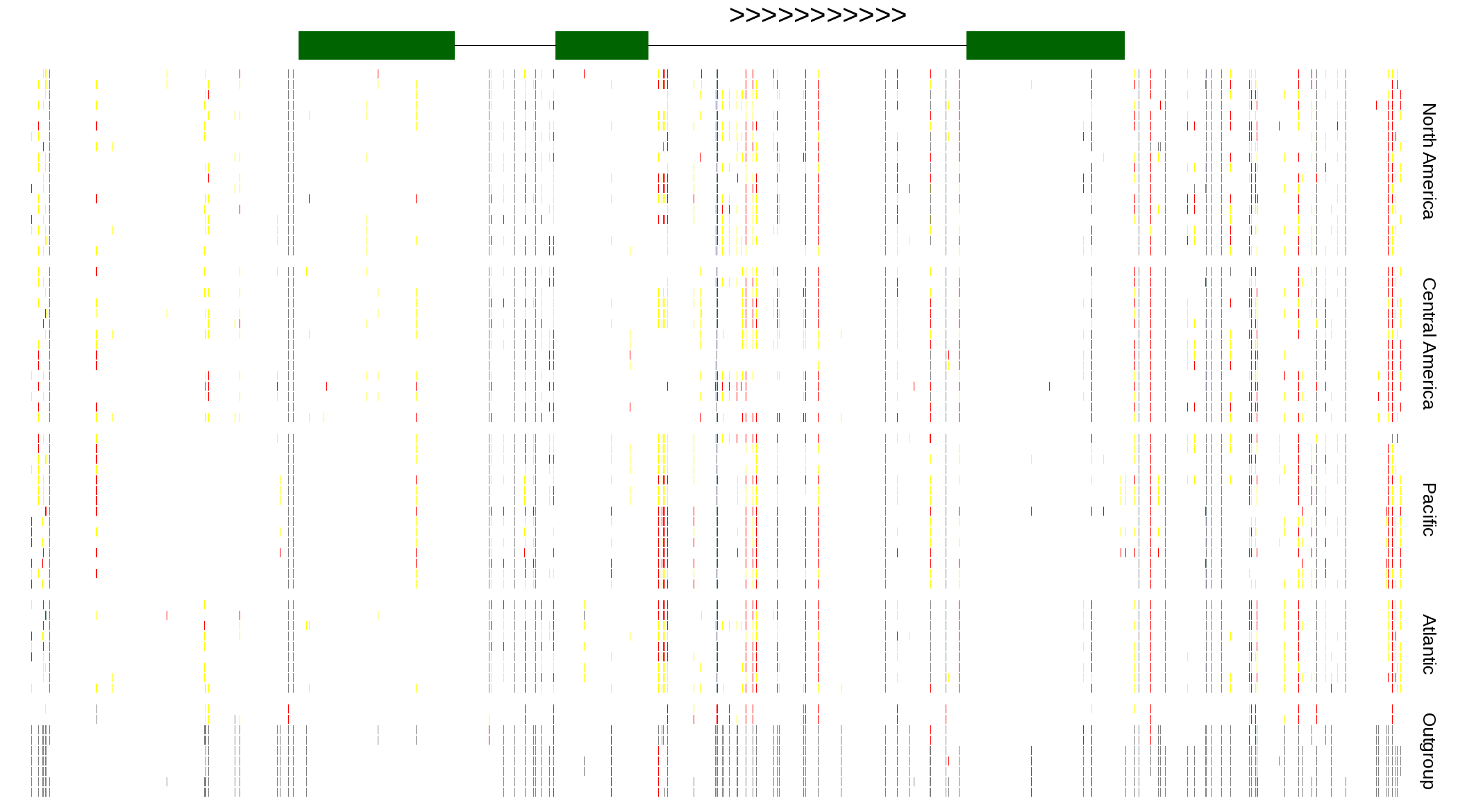
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS204125-TA
ATGTATTATAATCAAACAATTGTTCCAGATCCTACATTGACATACGACCAAATATATAACACAACGACTTACGCCCAAATACCGCGTTATATACAAACAGACAGATACAATGGTAGCAGTACTAGTTATAACAATAGTCGTTTAAATGATACCAAAGAAAATTTATTTAAGTTTCAAGACAGATATGAGATAAGTAGCAAGAGAGACCTCCTCGTTGGATTCGCACACGATCCATTCAGATACTCAATACCAGAAGCTGATTACGCTAAAGGAGTAAGAGTAGTGAACCCCCAGAGGGTAAACAGTGACCGAGGTAAGCGTGGTGTGGTTCATCTGTACAATATGTTAACCTGTGCCACGGGCTGCGATCCTGTATCATACAAGGGTTACGGCTGCTATTGTGGATTCCTTGGGTCCGGGCGACCCACCGATGGAATCGATAATTGCTGTAGACTGCATGACGAATGTTACGAGAATATCTACTGTCCATTCTACACGGTCTATTTCCAGCCGTACTACTGGAAATGCTATCATGGAGAGCCGCTCTGTGCTCTGGAGAACTTCCAGACCCACCCTGAGGCTGTGAACGGCTGTGCCGGCAGGCTGTGCGAATGTGACAGACGTTTTGCTATGTGCGTTAAGAAATATTCTTGTCCGCGAGGCCGGGCGCTATGTAAATCCTCGCCTCTGAGGCTCATACAAAATATTCTTATGTTCAAATAA
>DPOGS204125-PA
MYYNQTIVPDPTLTYDQIYNTTTYAQIPRYIQTDRYNGSSTSYNNSRLNDTKENLFKFQDRYEISSKRDLLVGFAHDPFRYSIPEADYAKGVRVVNPQRVNSDRGKRGVVHLYNMLTCATGCDPVSYKGYGCYCGFLGSGRPTDGIDNCCRLHDECYENIYCPFYTVYFQPYYWKCYHGEPLCALENFQTHPEAVNGCAGRLCECDRRFAMCVKKYSCPRGRALCKSSPLRLIQNILMFK-