| DPOGS204523 | ||
|---|---|---|
| Transcript | DPOGS204523-TA | 999 bp |
| Protein | DPOGS204523-PA | 332 aa |
| Genomic position | DPSCF300297 - 419287-421858 | |
| RNAseq coverage | 1144x (Rank: top 11%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL008730 | 0.0 | 96.69% | |
| Bombyx | BGIBMGA004302-TA | 0.0 | 93.37% | |
| Drosophila | eIF-2alpha-PA | 3e-131 | 73.83% | |
| EBI UniRef50 | UniRef50_E2B063 | 1e-155 | 83.95% | Eukaryotic translation initiation factor 2 subunit 1 n=13 Tax=Bilateria RepID=E2B063_CAMFO |
| NCBI RefSeq | NP_001037516.1 | 0.0 | 93.07% | eukaryotic translation initiation factor 2 alpha subunit [Bombyx mori] |
| NCBI nr blastp | gi|27462592 | 0.0 | 93.96% | eIF2 alpha subunit [Spodoptera frugiperda] |
| NCBI nr blastx | gi|27462592 | 4e-173 | 93.96% | eIF2 alpha subunit [Spodoptera frugiperda] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0003743 | 6.5e-39 | translation initiation factor activity | |
| GO:0003723 | 6.5e-39 | RNA binding | ||
| GO:0005850 | 6.5e-39 | eukaryotic translation initiation factor 2 complex | ||
| KEGG pathway | nvi:100119627 | 2e-156 | ||
| K03237 (eIF-2A, EIF2S1) | maps-> | Protein processing in endoplasmic reticulum | ||
| InterPro domain | [186-308] IPR024055 | 7.8e-51 | Translation initiation factor 2, alpha subunit, C-terminal | |
| [128-242] IPR011488 | 6.5e-39 | Translation initiation factor 2, alpha subunit | ||
| [5-91] IPR012340 | 3.3e-37 | Nucleic acid-binding, OB-fold | ||
| [92-180] IPR024054 | 9.2e-35 | Translation initiation factor 2, alpha subunit, middle domain | ||
| [2-88] IPR016027 | 1.5e-20 | Nucleic acid-binding, OB-fold-like | ||
| [13-87] IPR003029 | 9.2e-18 | Ribosomal protein S1, RNA-binding domain | ||
| [14-87] IPR022967 | 1.1e-14 | RNA-binding domain, S1 | ||
| Orthology group | MCL13464 | Single-copy universal gene | ||
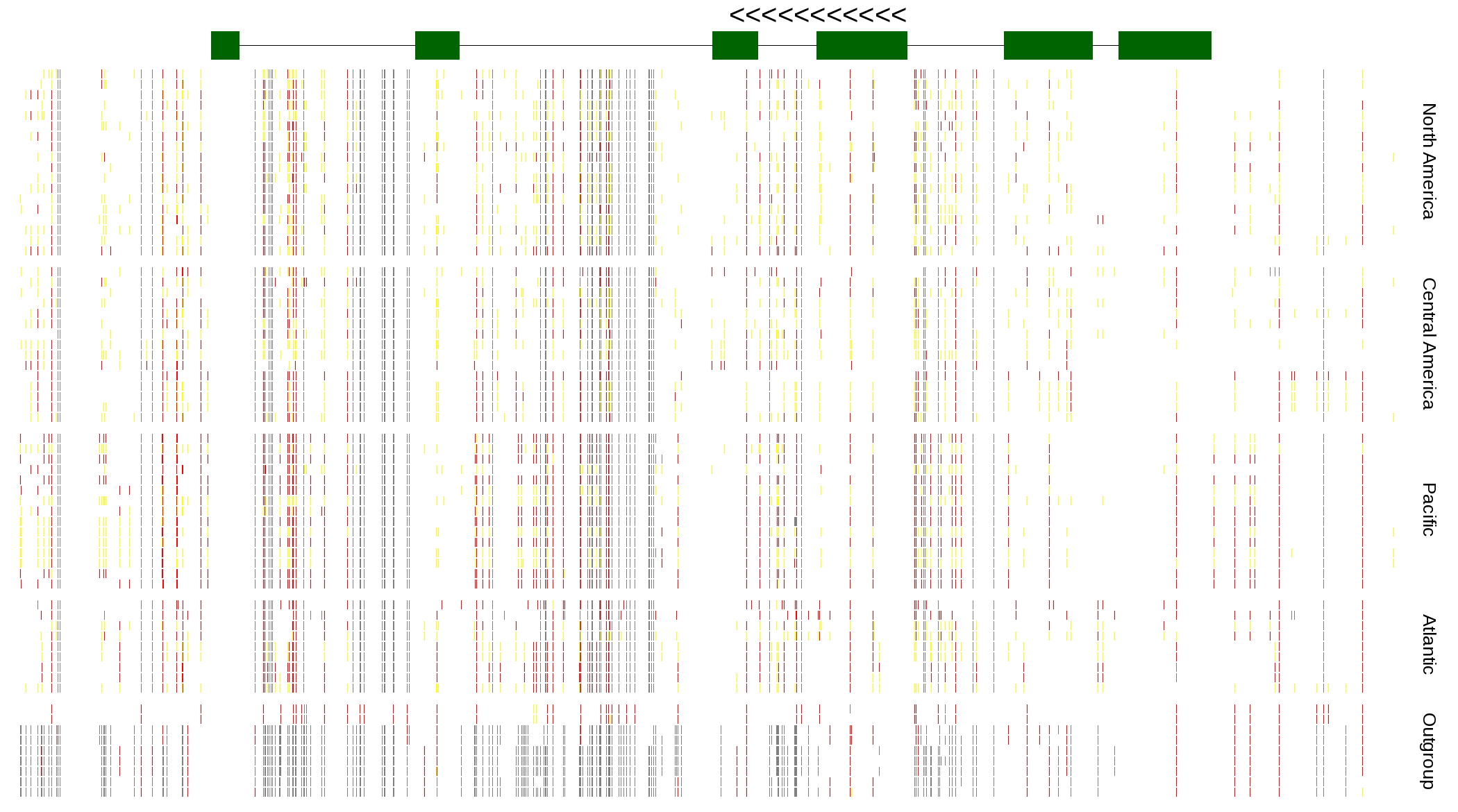
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS204523-TA
ATGCCGTTGTCGTGTCGATTTTATCAAGAAAAATATCCAGAAGTAGAAGATGTGGTGATGGTGAACGTTAGGTCTATAGCTGAGATGGGTGCATACGTTCACCTGCTCGAATATAACAATATAGAGGGCATGATTTTGCTTTCTGAATTGTCCAGAAGACGTATCCGTTCCATAAACAAGTTGATTAGAGTAGGGAAGACAGAACCGGTCGTAGTTATCAGAGTAGACAAAGAAAAAGGTTACATTGATTTGTCGAAACGTCGTGTATCAGCCGAGGATATCGACAAATGTACTGAGAGGTACGCCAAAGCTAAAGCTGTGAACTCCATTTTGCGTCACGTAGCAGAACTGCTGCACTACCAAAGCTCGGAACAGCTGGAAGAGCTTTATAAACAGACAGCTTGGCACTTCGAAGAGAAATATAAAAAGAAAGCATCTGCTTACGACTTCTTTAAACAAGCCGCTGTAGATCCCTCTGTGCTCAATGAATGTGGTCTGGATGAGAAAACCAAGGAAGTGCTATTAGCTAACATCAAACGGAAACTGACTTCCCAGGCTGTGAAGATCCGAGCTGATATTGAATGTGCCTGTTACGGCTATGAGGGTATTGACGCCGTGAAGGAGGCATTGAAAGCTGGCTTGTCTCTCTCAACCCCAGATATGCCTATTAAAATCAACCTCATAGCCCCACCTTTGTATGTAATGACAACTTCTACCCCGGAGAAGACCGATGGGCTCAAAGCTTTGCAAGACGCAATCGATAAAATCAAAGATACAATCACCACTGCCGGTGGAGTGTTCAACATTCAGATGGCTCCTAAGGTTGTCACCGCAACGGATGAGGCAGAGTTGGCAAGACAGATGGAACGTGCAGAGGCTGAGAATGCAGAGGTCGCTGGTGACTCAGCAGAGGAAGATGCCGACCAAGGCATGGGCGATGCTGGTATGGATGAAGAACCACAACAGAACGGGGCTTCGGATGACACTGATGAGAATTGA
>DPOGS204523-PA
MPLSCRFYQEKYPEVEDVVMVNVRSIAEMGAYVHLLEYNNIEGMILLSELSRRRIRSINKLIRVGKTEPVVVIRVDKEKGYIDLSKRRVSAEDIDKCTERYAKAKAVNSILRHVAELLHYQSSEQLEELYKQTAWHFEEKYKKKASAYDFFKQAAVDPSVLNECGLDEKTKEVLLANIKRKLTSQAVKIRADIECACYGYEGIDAVKEALKAGLSLSTPDMPIKINLIAPPLYVMTTSTPEKTDGLKALQDAIDKIKDTITTAGGVFNIQMAPKVVTATDEAELARQMERAEAENAEVAGDSAEEDADQGMGDAGMDEEPQQNGASDDTDEN-