| DPOGS205422 | ||
|---|---|---|
| Transcript | DPOGS205422-TA | 849 bp |
| Protein | DPOGS205422-PA | 282 aa |
| Genomic position | DPSCF300407 + 353897-355100 | |
| RNAseq coverage | 19x (Rank: top 80%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL022322 | 5e-119 | 71.48% | |
| Bombyx | BGIBMGA001592-TA | 4e-101 | 63.29% | |
| Drosophila | Vha36-3-PA | 3e-39 | 39.62% | |
| EBI UniRef50 | UniRef50_Q1HPT6 | 7e-99 | 63.29% | Vacuolar ATP synthase subunit D n=2 Tax=Obtectomera RepID=Q1HPT6_BOMMO |
| NCBI RefSeq | NP_001040532.1 | 1e-99 | 63.29% | vacuolar ATP synthase subunit D [Bombyx mori] |
| NCBI nr blastp | gi|114053147 | 2e-98 | 63.29% | vacuolar ATP synthase subunit D [Bombyx mori] |
| NCBI nr blastx | gi|114053147 | 6e-93 | 63.29% | vacuolar ATP synthase subunit D [Bombyx mori] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0033178 | 4.2e-46 | proton-transporting two-sector ATPase complex, catalytic domain | |
| GO:0015991 | 4.2e-46 | ATP hydrolysis coupled proton transport | ||
| GO:0042626 | 4.2e-46 | ATPase activity, coupled to transmembrane movement of substances | ||
| GO:0046961 | 4.2e-46 | proton-transporting ATPase activity, rotational mechanism | ||
| KEGG pathway | phu:Phum_PHUM603950 | 7e-38 | ||
| K02149 (ATPeVD, ATP6M) | maps-> | Collecting duct acid secretion | ||
| Oxidative phosphorylation | ||||
| Phagosome | ||||
| Vibrio cholerae infection | ||||
| Epithelial cell signaling in Helicobacter pylori infection | ||||
| InterPro domain | [15-210] IPR002699 | 4.2e-46 | ATPase, V1/A1 complex, subunit D | |
| Orthology group | MCL26600 | Lepidoptera specific | ||
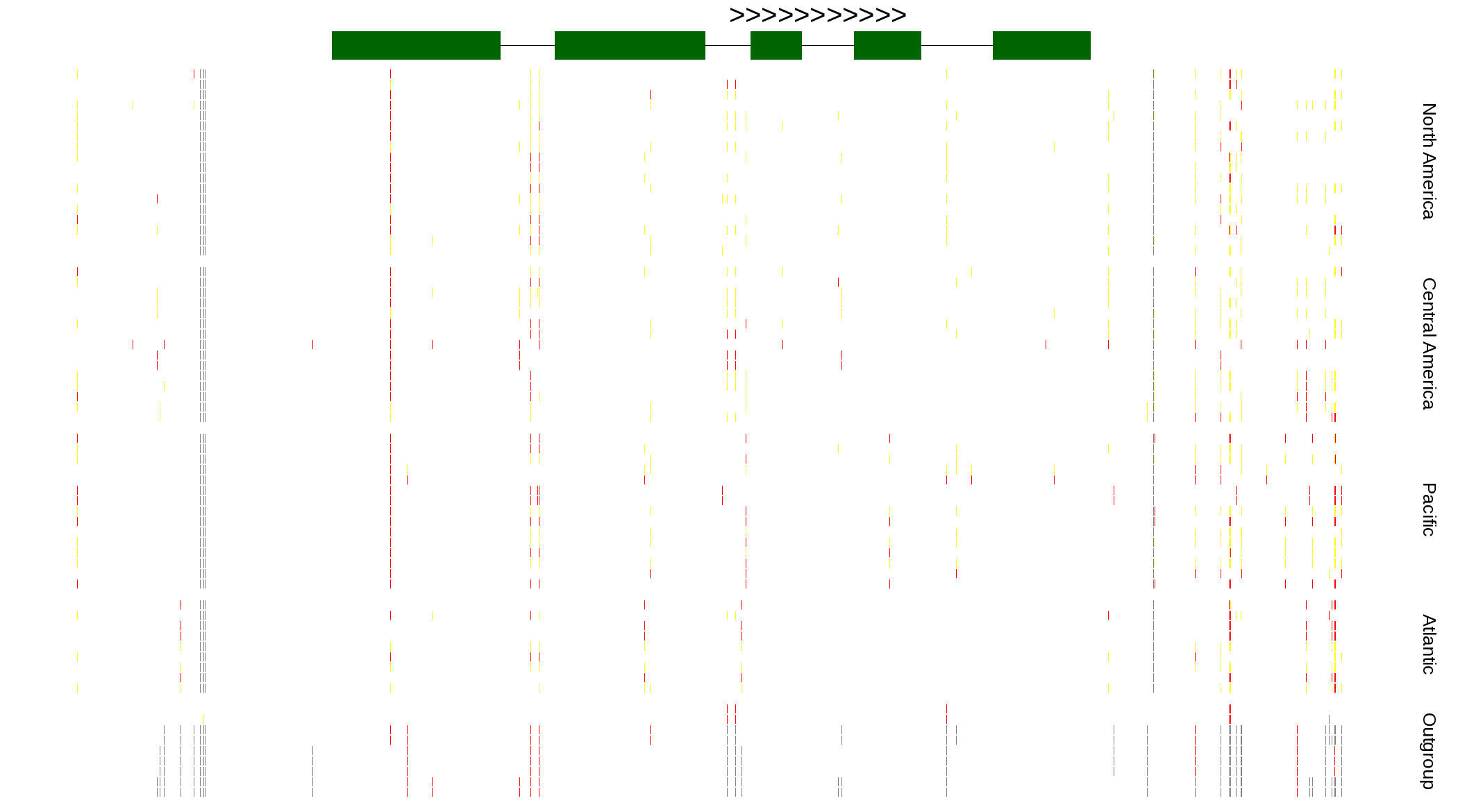
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS205422-TA
ATGAATTCGGAAAACCGTTATCCTGTAACGGCATCTTTATTTATGTTACGTGAAATAAAAAATCGACAAGAAAAGGTCAGCAGAGGATATCAACTTCTTAAGAAAAAAGCAGAAGCTCTCCGTATCCGCGGCCGTCAGGCAGCTGCTGAATTGGCTACGACACAAGCGATTTTGGGACATGCTTTAAGAGAAGCTTATATATCTTTGGCTGCTATTAAATTCACCAACGGCGAATCCAATGCCTTAGTTTTAGAAAATGTTGGCGAAGCTCAAATCCGAGTACAACGTGTGCCGGAAAATATTTCGGGAGTTGCTACCGTGTCTTTGCAGGTATTGGAAGATACTACAGCAAACGATTCATTGCGATATGCAGGACTGGGTGCTGGAGGGCATCGTACCACCGAAACCAAAAAGGCTTTTCGAGAAGCCATTAAGATATTAATAAGATTTGCTTCCCTGAGAAGTAACTGTGTGTTGCTAGATGAAGCTATAAAATCTGCCTTGAGAAAAGTTAATGGCATAGAAAAAGTAATAATGCCTAAGCTACGAAATACTGAAAATTACATTTTAATGGAAATGGATGAAAGGGAACGTGAAGAATTTCATAGACTAAAAATGGTGAAAGCTAAGAAAAACCTTGGACAGCCACTTTTAAAGTCGAAGTCGAACAGGAAATTTCCCTTTGGTGACAGTGATAAAGCTAAATCCTCTTTGGAGTCTATAGATAATCATCTGGAATCTTTGGAGATCTGTTCTTGCCCAACATTATCGACAACCACTGTGTCAGCTGGAGACTTTAAACCAGTGTGCTATCCTCATAATTGGGATGACGAGGATTTACTATTTTAA
>DPOGS205422-PA
MNSENRYPVTASLFMLREIKNRQEKVSRGYQLLKKKAEALRIRGRQAAAELATTQAILGHALREAYISLAAIKFTNGESNALVLENVGEAQIRVQRVPENISGVATVSLQVLEDTTANDSLRYAGLGAGGHRTTETKKAFREAIKILIRFASLRSNCVLLDEAIKSALRKVNGIEKVIMPKLRNTENYILMEMDEREREEFHRLKMVKAKKNLGQPLLKSKSNRKFPFGDSDKAKSSLESIDNHLESLEICSCPTLSTTTVSAGDFKPVCYPHNWDDEDLLF-