| DPOGS206432 | ||
|---|---|---|
| Transcript | DPOGS206432-TA | 633 bp |
| Protein | DPOGS206432-PA | 210 aa |
| Genomic position | DPSCF300070 - 889752-891051 | |
| RNAseq coverage | 4078x (Rank: top 3%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL012702 | 3e-83 | 92.81% | |
| Bombyx | BGIBMGA005439-TA | 2e-113 | 90.00% | |
| Drosophila | CG9172-PB | 7e-90 | 76.85% | |
| EBI UniRef50 | UniRef50_O75251 | 2e-80 | 85.35% | NADH dehydrogenase [ubiquinone] iron-sulfur protein 7, mitochondrial n=652 Tax=root RepID=NDUS7_HUMAN |
| NCBI RefSeq | NP_001040456.1 | 7e-112 | 90.00% | NADH-ubiquinone oxidoreductase Fe-S protein 7 [Bombyx mori] |
| NCBI nr blastp | gi|114052144 | 1e-110 | 90.00% | NADH-ubiquinone oxidoreductase Fe-S protein 7 [Bombyx mori] |
| NCBI nr blastx | gi|114052144 | 3e-110 | 90.43% | NADH-ubiquinone oxidoreductase Fe-S protein 7 [Bombyx mori] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0016651 | 8.8e-129 | oxidoreductase activity, acting on NADH or NADPH | |
| GO:0051539 | 8.8e-129 | 4 iron, 4 sulfur cluster binding | ||
| GO:0055114 | 8.8e-129 | oxidation-reduction process | ||
| GO:0048038 | 1.7e-76 | quinone binding | ||
| GO:0008137 | 1.7e-76 | NADH dehydrogenase (ubiquinone) activity | ||
| KEGG pathway | ame:408909 | 1e-91 | ||
| K03940 (NDUFS7) | maps-> | Huntington's disease | ||
| Oxidative phosphorylation | ||||
| Alzheimer's disease | ||||
| Parkinson's disease | ||||
| InterPro domain | [53-210] IPR014406 | 8.8e-129 | [NiFe]-hydrogenase-3-type complex, small subunit/NADH:quinone oxidoreductase, subunit NuoB | |
| [61-200] IPR006138 | 1.7e-76 | NADH-ubiquinone oxidoreductase, 20 Kd subunit | ||
| [72-201] IPR006137 | 9.8e-45 | NADH:ubiquinone oxidoreductase-like, 20kDa subunit | ||
| Orthology group | MCL11080 | Multiple-copy universal gene | ||
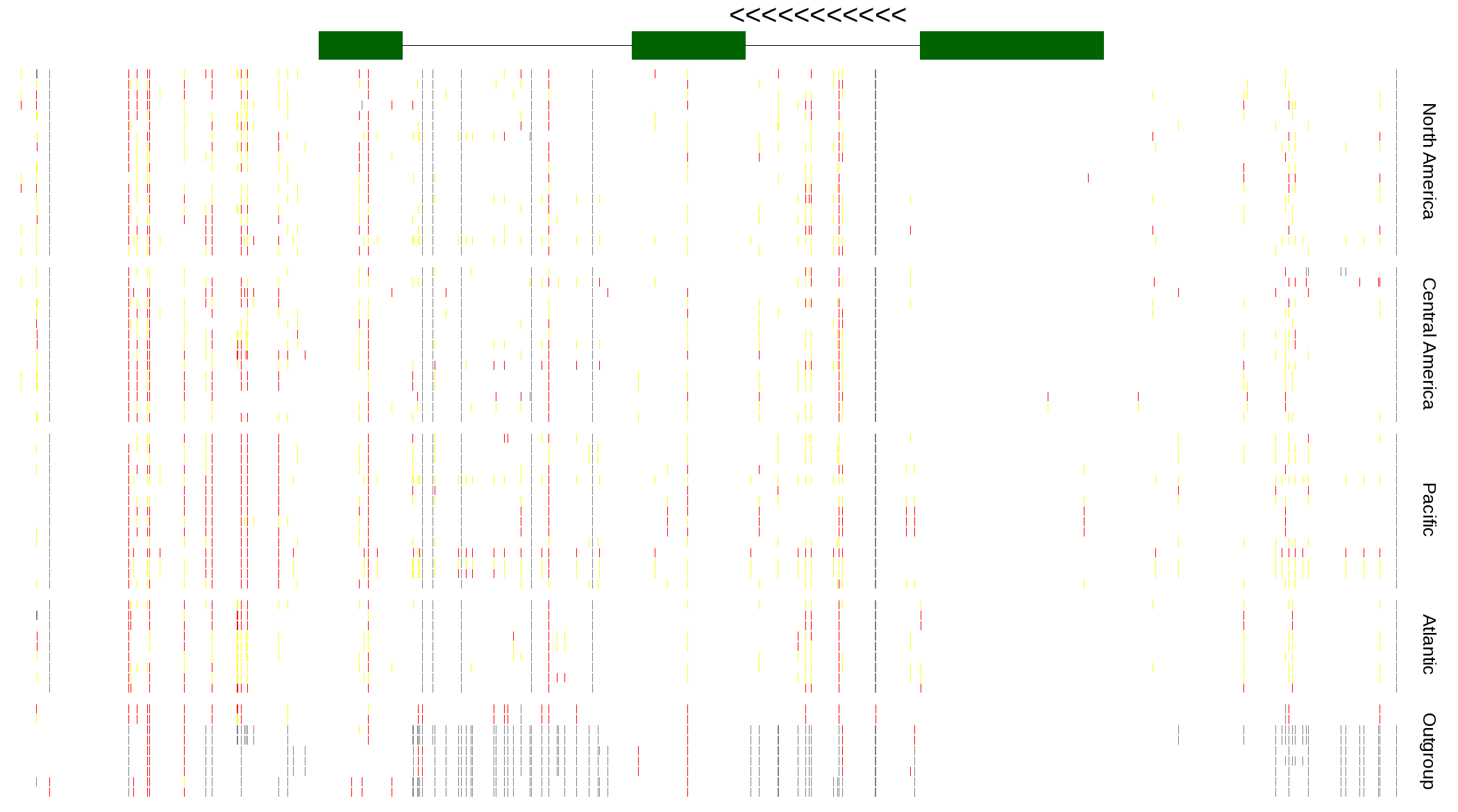
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS206432-TA
ATGCAAGCTATCAAGGCTTTGGGGGCTGCAGCCCCGGCTACAGTTATGTCTGTAGTAAAAAAAGGTGCATTCACGCCTGTAGTGGAACAAGTACGTCGTACTCATTTGCCGGCACCAAACCCTAAGGAAAATAGACCATATTCTCCTTTCCAAGATACCAGTAATGCGGGAGAATATGCTGTGGCAAGATTAGATGATTTATTGAATTGGGGAAGGAAGGGTTCTATGTGGCCCATGACATTTGGATTAGCTTGTTGCGCTGTTGAGATGATGCACATTGCAGCCCCCCGATATGATATGGACAGATATGGTGTTGTGTTCCGAGCATCCCCTCGTCAGTCTGATGTCATGATAGTTGCTGGTACTTTAACCAACAAGATGGCTCCAGCTTTGAGGAAAGTGTATGATCAAATGCCCGAGCCGAGATGGGTTATATCTATGGGAAGTTGTGCCAATGGTGGTGGATATTATCACTACTCTTATTCTGTTGTAAGAGGTTGTGATCGTATTGTGCCAGTTGACATTTATGTTCCTGGTTGTCCACCGACTGCAGAAGCTTTGTTGTATGGTGTTTTACAATTGCAAAAGAAAGTAAAGAGAATGAAAACTGTTCAAGTATGGTACAGAAAGTAA
>DPOGS206432-PA
MQAIKALGAAAPATVMSVVKKGAFTPVVEQVRRTHLPAPNPKENRPYSPFQDTSNAGEYAVARLDDLLNWGRKGSMWPMTFGLACCAVEMMHIAAPRYDMDRYGVVFRASPRQSDVMIVAGTLTNKMAPALRKVYDQMPEPRWVISMGSCANGGGYYHYSYSVVRGCDRIVPVDIYVPGCPPTAEALLYGVLQLQKKVKRMKTVQVWYRK-