| DPOGS206453 | ||
|---|---|---|
| Transcript | DPOGS206453-TA | 2787 bp |
| Protein | DPOGS206453-PA | 928 aa |
| Genomic position | DPSCF300070 - 153540-156326 | |
| RNAseq coverage | 312x (Rank: top 36%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL012943 | 0.0 | 96.99% | |
| Bombyx | BGIBMGA005466-TA | 0.0 | 94.94% | |
| Drosophila | alpha-Adaptin-PB | 0.0 | 82.28% | |
| EBI UniRef50 | UniRef50_O94973 | 0.0 | 69.59% | AP-2 complex subunit alpha-2 n=254 Tax=Opisthokonta RepID=AP2A2_HUMAN |
| NCBI RefSeq | XP_971368.1 | 0.0 | 84.75% | PREDICTED: similar to AGAP009538-PA [Tribolium castaneum] |
| NCBI nr blastp | gi|91092680 | 0.0 | 84.75% | PREDICTED: similar to AGAP009538-PA [Tribolium castaneum] |
| NCBI nr blastx | gi|332024683 | 0.0 | 85.21% | AP-2 complex subunit alpha [Acromyrmex echinatior] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0016020 | 0 | membrane | |
| GO:0008565 | 0 | protein transporter activity | ||
| GO:0015031 | 0 | protein transport | ||
| GO:0005488 | 7.7e-213 | binding | ||
| GO:0006886 | 1.1e-154 | intracellular protein transport | ||
| GO:0030117 | 1.1e-154 | membrane coat | ||
| GO:0016192 | 1.1e-154 | vesicle-mediated transport | ||
| GO:0030131 | 3.8e-45 | clathrin adaptor complex | ||
| KEGG pathway | tca:660011 | 0.0 | ||
| K11824 (AP2A) | maps-> | Huntington's disease | ||
| Endocytosis | ||||
| InterPro domain | [1-929] IPR017104 | 0 | Adaptor protein complex AP-2, alpha subunit | |
| [6-617] IPR011989 | 7.7e-213 | Armadillo-like helical | ||
| [30-587] IPR002553 | 1.1e-154 | Clathrin/coatomer adaptor, adaptin-like, N-terminal | ||
| [8-593] IPR016024 | 5.4e-112 | Armadillo-type fold | ||
| [816-928] IPR015873 | 1.4e-47 | Clathrin alpha-adaptin/coatomer adaptor, appendage, C-terminal subdomain | ||
| [815-928] IPR009028 | 7e-46 | Clathrin/coatomer adaptor, adaptin-like, appendage, C-terminal subdomain | ||
| [693-815] IPR013038 | 3.8e-45 | Clathrin adaptor, alpha-adaptin, appendage, Ig-like subdomain | ||
| [815-923] IPR003164 | 7.6e-43 | Clathrin adaptor, alpha-adaptin, appendage, C-terminal subdomain | ||
| [684-814] IPR013041 | 2e-36 | Clathrin/coatomer adaptor, adaptin-like, appendage, Ig-like subdomain | ||
| [698-809] IPR008152 | 2.5e-26 | Clathrin adaptor, alpha/beta/gamma-adaptin, appendage, Ig-like subdomain | ||
| Orthology group | MCL11387 | Multiple-copy universal gene | ||
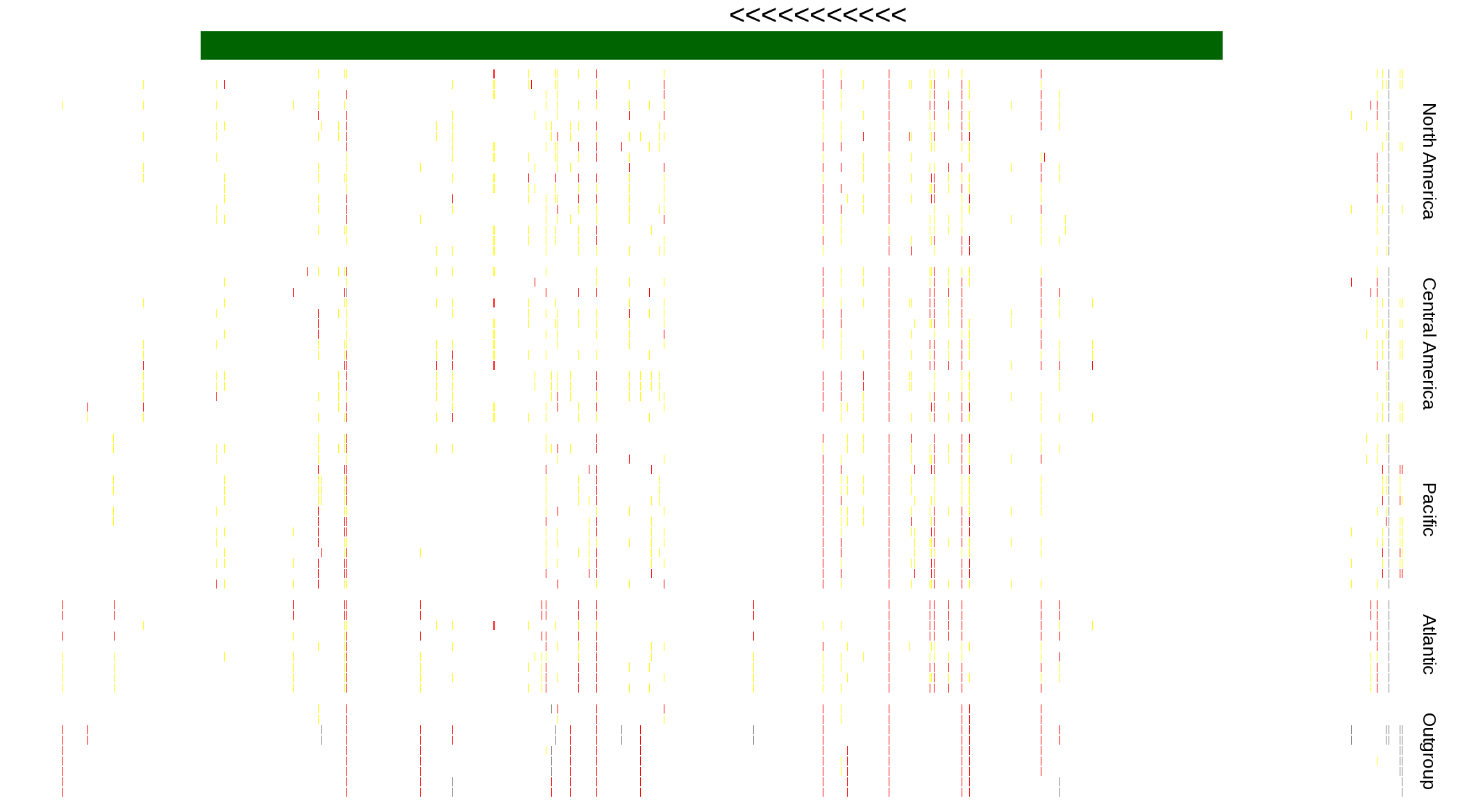
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS206453-TA
ATGCCTGCCGTCAGAGGAGATGGAATGCGAGGACTCGCAGTTTTTATATCAGATATACGGAATTGTAAGAGTAAAGAAGCAGAAATAAAAAGAATTAATAAAGAACTGGCTAACATACGTAGTAAATTTAAAGGTGACAAAACCTTAGATGGATATCAGAAGAAGAAGTATGTCTGCAAACTCCTGTTTATCTTTCTGTTGGGTCATGATATTGATTTCGGTCATATGGAAGCAGTGAACTTACTGTCCTCTAATAAATACTCAGAGAAGCAAATTGGATATCTTTTTATATCAGTTTTGGTAAATACTAATAGTGATCTCATAAAACTTATCATACAGAGCATTAAAAATGACTTGCAGTCTCGAAACCCTATTCACGTAAATCTTGCACTACAATGTATAGCTAATATTGGTAGTAAGGATATGGCTGAGGCTTTTGGAACCGAGATTCCAAAATTACTAGTCTCTGGTGACACCATGGATGTAGTCAAGCAGTCAGCAGCACTATGTCTTCTCAGATTGTTTCGTAAGTGTCCAGAAATTATTCCAGGAGGAGAATGGACTTCAAGAATCATACATTTGCTGAATGACCCACATATGGGGGTAGTCACTGCTGCCACATCTCTTATAGATGCACTTGTTAAGAAAAATCCAGAAGAATATAAAGGATGTGTCACACTGGCTGTGGCCCGCCTTAGTAGGATTGTTACAGCAAGTTACACTGATTTACAGGATTATACATATTATTTTGTGCCAGCCCCTTGGTTATCTGTTAAACTTTTGCGCTTACTCCAGAACTACACCCCACCTTCAGAAGAGCCTGGAGTTCGTGGACGTTTATCTGAGTGCTTGGAAACCATATTTAATAAAGCTCAAGAGCCACCTAAGTCAAAGAAAGTGCAACATTCGAATGCAAAGAATGCTGTTCTCTTTGAAGCAATAAGTCTTATAATTCACAATGATAGTGAACCTAATTTACTAGTTAGGGCATGCAATCAGCTTGGACAATTTTTAAGTAACAGAGAAACTAATTTGAGATACTTGGCACTTGAGTCAATGTGCCACCTTGCAACATCAGAATTTTCCCACGAAGCTGTTAAAAAACATCAGGAAGTTGTAATTTTATCTATGAAAATGGAAAAGGATGTGTCTGTTAGACAGCAAGCTGTAGATTTACTATATGCCATGTGTGATAAAACAAATGCTGAAGAAATTGTCCAAGAAATGTTGGCTTATCTTGAAACAGCTGATTATTCAATCAGAGAAGAAATGGTCCTCAAAGTTGCCATATTATCTGAAAAATATGCTACTGACTTCACTTGGTATGTTGATGTCATATTAAACCTTATAAGAATAGCTGGAGATTATGTTTCAGAGGAAGTGTGGTATAGAGTTATTCAAATTGTCATAAACAGAGATGAAGTCCAAGGATATGCAGCAAAAACTGTTTTTGAAGCCCTTCAAGCTCCAACTTGTCATGAAAATATGGTAAAAGTGGGTGGATACATACTGGGTGAATTTGGAAACTTAATTGCTGGTGATACAAGATCTTCACCACAAGTCCAATTTGAACTGCTACATTCAAAGTATCATCTTTGTTCTGCAGCTACAAGAGCACTGTTATTGTCAACTTACATTAAACTGGTAAATCTCTTCCCTGAAATTAAAAACAGAGTGCAAGAAGTTTTCCGTGCTGACTCAAATTTGCGATCTGCTGATGTAGAATTACAACAAAGGGCATCAGAATATCTGCAATTAAGTATAGTTGCCAGTTCAGACGTATTAGCAACAGTTTTGGAAGAAATGCCTGCATTCCCAGAACGGGAATCATCAATTTTGGCTGTACTGAAAAAGAAGAAACCAGGTCGCATACCTGATGATGTAAAGGAGTCTAAGAGTCCTCAACCCAGTATCACACCAGCTCCAGTTATTAATAATTCTATAAACAGCAATAATTCCAGTGCTGATCTTCTTGGTTTATCAACTCCTCCTGGTACTAATGCCACTACAGGAAATGGTTTATTAGATGTTCTTGGAGACTTATACTCTACACCCAAGAAAAGCCCAATCACTGTACAACAAAATAATATTAAGAAATTCTTGTTTAAGAATAATGGAGTACTCTTTGAAAATGATCTCATACAAATTGGCGTTAAAAGTGAATTCAGACAGAATTTGGGAAGAATCGGACTATTTTATGGTAATAAGACACAATCTGCTATTCAAAATGTCCATCCTGAACTACATTGGACTGATTTGCACAAACTGAATGTGCAGATGAAACCTATGGAACCTGTTCTGGAAGCAGGTGCTCAAATTCAACAAATGCTAACAGCTGAGTGCATTGAAGACTTTGCTGATGCACCAAGTATGTCAGTGTCATTCCTGTACAACAATGTTCCACAGAAAATCTCAATGAAACTGCCCTTAACACTAAATAAATTCTTTGAACCAACTGAAATGAATGGAGAATCATTTTTCGCTAGGTGGAAGAATTTAGGTGGTGAACAACAAAGGGCGCAAAAAATTTTCAAAGCTCAAGGCGCAATAGATATCCCAGCCACCCGAACTAAACTGGCTGGTTTCGGTATGCAATTATTAGATGGTATTGATCCCAATCCTGACAACTTTGTGTGTGCAGGAATTGTACATACAAGAGTTCAGCAGGTAGGATGCTTAATGAGATTGGAACCTAACAAACAAGCTCAAATGTTTAGACTTACTGTTAGATCAAGTAAAGAAACGGTCTCACAGGAAATATGTAATTTGCTAGCTGATCAATTCTAA
>DPOGS206453-PA
MPAVRGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKTLDGYQKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNKYSEKQIGYLFISVLVNTNSDLIKLIIQSIKNDLQSRNPIHVNLALQCIANIGSKDMAEAFGTEIPKLLVSGDTMDVVKQSAALCLLRLFRKCPEIIPGGEWTSRIIHLLNDPHMGVVTAATSLIDALVKKNPEEYKGCVTLAVARLSRIVTASYTDLQDYTYYFVPAPWLSVKLLRLLQNYTPPSEEPGVRGRLSECLETIFNKAQEPPKSKKVQHSNAKNAVLFEAISLIIHNDSEPNLLVRACNQLGQFLSNRETNLRYLALESMCHLATSEFSHEAVKKHQEVVILSMKMEKDVSVRQQAVDLLYAMCDKTNAEEIVQEMLAYLETADYSIREEMVLKVAILSEKYATDFTWYVDVILNLIRIAGDYVSEEVWYRVIQIVINRDEVQGYAAKTVFEALQAPTCHENMVKVGGYILGEFGNLIAGDTRSSPQVQFELLHSKYHLCSAATRALLLSTYIKLVNLFPEIKNRVQEVFRADSNLRSADVELQQRASEYLQLSIVASSDVLATVLEEMPAFPERESSILAVLKKKKPGRIPDDVKESKSPQPSITPAPVINNSINSNNSSADLLGLSTPPGTNATTGNGLLDVLGDLYSTPKKSPITVQQNNIKKFLFKNNGVLFENDLIQIGVKSEFRQNLGRIGLFYGNKTQSAIQNVHPELHWTDLHKLNVQMKPMEPVLEAGAQIQQMLTAECIEDFADAPSMSVSFLYNNVPQKISMKLPLTLNKFFEPTEMNGESFFARWKNLGGEQQRAQKIFKAQGAIDIPATRTKLAGFGMQLLDGIDPNPDNFVCAGIVHTRVQQVGCLMRLEPNKQAQMFRLTVRSSKETVSQEICNLLADQF-