| DPOGS207002 | ||
|---|---|---|
| Transcript | DPOGS207002-TA | 2718 bp |
| Protein | DPOGS207002-PA | 905 aa |
| Genomic position | DPSCF300001 + 1017227-1023866 | |
| RNAseq coverage | 921x (Rank: top 14%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL008671 | 0.0 | 90.88% | |
| Bombyx | BGIBMGA012922-TA | 0.0 | 85.09% | |
| Drosophila | Bap-PA | 0.0 | 81.31% | |
| EBI UniRef50 | UniRef50_Q10567 | 0.0 | 71.89% | AP-1 complex subunit beta-1 n=250 Tax=Eukaryota RepID=AP1B1_HUMAN |
| NCBI RefSeq | XP_002057979.1 | 0.0 | 81.08% | GJ15746 [Drosophila virilis] |
| NCBI nr blastp | gi|195398741 | 0.0 | 81.08% | GJ15746 [Drosophila virilis] |
| NCBI nr blastx | gi|194893157 | 0.0 | 82.17% | GG19251 [Drosophila erecta] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0008565 | 0 | protein transporter activity | |
| GO:0015031 | 0 | protein transport | ||
| GO:0005488 | 1.9e-205 | binding | ||
| GO:0006886 | 7.8e-165 | intracellular protein transport | ||
| GO:0030117 | 7.8e-165 | membrane coat | ||
| GO:0016192 | 7.8e-165 | vesicle-mediated transport | ||
| GO:0030131 | 2.9e-32 | clathrin adaptor complex | ||
| KEGG pathway | dvi:Dvir_GJ15746 | 0.0 | ||
| K12392 (AP1B1) | maps-> | Lysosome | ||
| InterPro domain | [1-759] IPR016342 | 0 | Adaptor protein complex, beta subunit | |
| [3-563] IPR011989 | 1.9e-205 | Armadillo-like helical | ||
| [17-533] IPR002553 | 7.8e-165 | Clathrin/coatomer adaptor, adaptin-like, N-terminal | ||
| [4-583] IPR016024 | 1.9e-150 | Armadillo-type fold | ||
| [791-904] IPR012295 | 1.3e-48 | Beta2-adaptin/TATA-box binding, C-terminal | ||
| [793-905] IPR009028 | 3.8e-47 | Clathrin/coatomer adaptor, adaptin-like, appendage, C-terminal subdomain | ||
| [681-789] IPR013037 | 2.9e-32 | Clathrin adaptor, beta-adaptin, appendage, Ig-like subdomain | ||
| [680-792] IPR013041 | 6.1e-31 | Clathrin/coatomer adaptor, adaptin-like, appendage, Ig-like subdomain | ||
| [794-904] IPR015151 | 7.8e-29 | Clathrin adaptor, beta-adaptin, appendage, C-terminal subdomain | ||
| [682-785] IPR008152 | 1.2e-08 | Clathrin adaptor, alpha/beta/gamma-adaptin, appendage, Ig-like subdomain | ||
| Orthology group | MCL11325 | Multiple-copy universal gene | ||
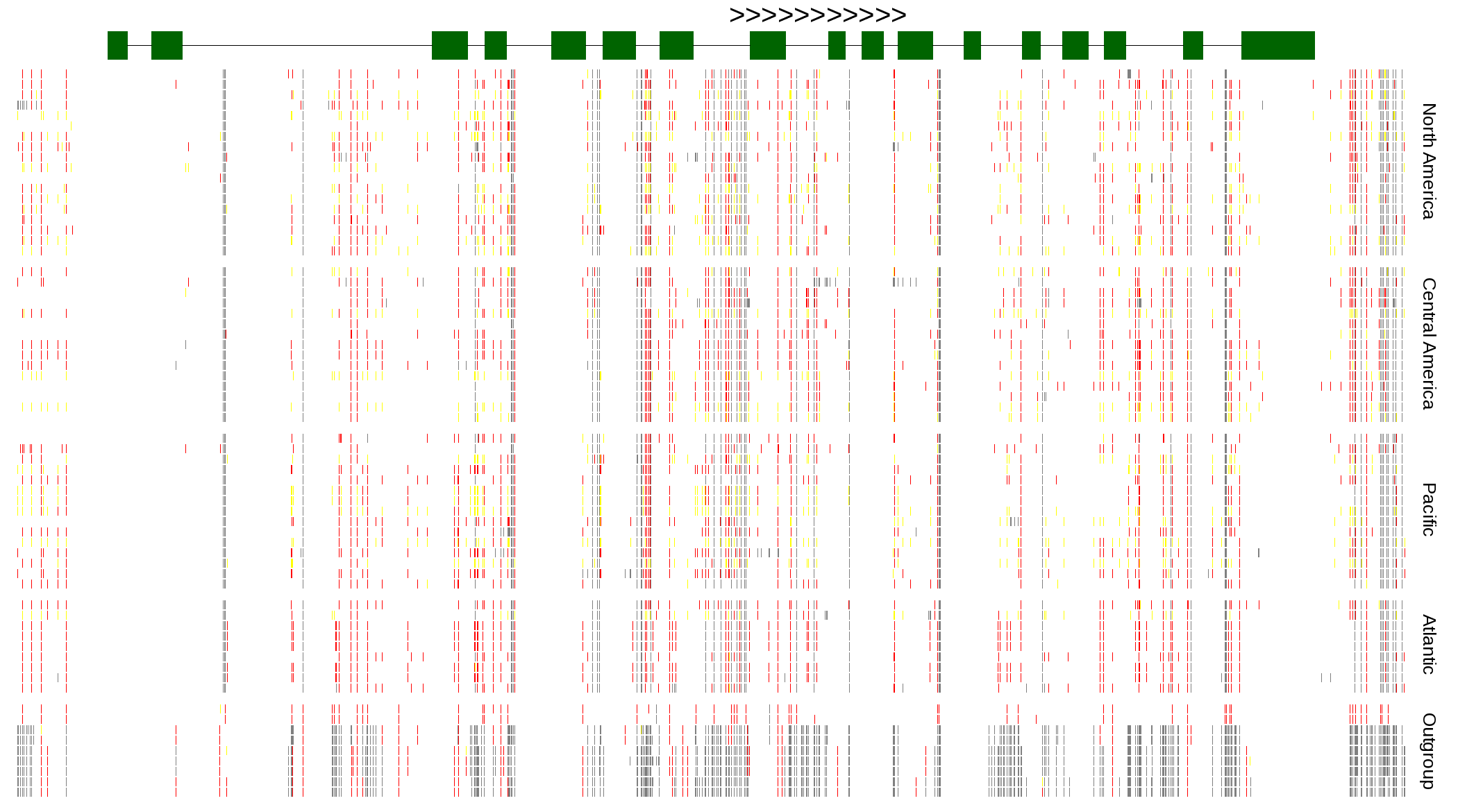
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS207002-TA
ATGACTGATTCAAAATACTTCACAACTACAAAGAAAGGCGAAATATTCGAGCTCAAGTCGGAGCTGAATAGCGATAAGAAAGAAAAGAAGAAGGAAGCTGTTAAAAAGGTGATAGCTTCCATGACCGTGGGCAAAGATGTGTCAGCTCTATTCCCTGATGTTGTTAATTGCATGCAAACCGACAACTTGGAACTCAAGAAGCTGGTATACTTGTACCTCATGAACTACGCCAAGTCCCAGCCGGATATGGCTATCATGGCTGTTAACACATTTGTCAAGGATTGCGAGGACTCGAATCCTTTGATCCGTGCTCTGGCTGTACGGACCATGGGTTGCATCCGAGTGGACAAGATCACGGAGTACCTCTGTGAGCCCTTACGGAAGTGTCTCAAGGATGAAGACCCCTATGTCAGGAAGACGGCTGCAGTGTGCGTCGCCAAACTGTACGACATATCACCCAGTATGGTGGAAGATCAGGGTTTCCTCGATCAGTTAAAGGATCTGTTGAGTGACTCAAATCCTATGGTTGTAGCGAACGCTGTCGCAGCTCTCTCTGAGATTAATGAGGCCAGTGTATCCGGACATCCGCTTGTAGAAATGAACGCCCCAACCATTAACAAGCTGCTGACAGCCCTGAACGAGTGCACGGAGTGGGGTCAGGTGTTCATACTGGACGCTCTTTCGAACTACTCCCCTCGTGATTCACGCGAGGCTCACTCTATATGCGAACGTATAACACCGCGTCTAGCCCACGCCAACGCCGCCGTCGTTCTGTCAGCCGTCAAGGTCCTCATGAAGCTCATGGAGATGTTATCAGATGAGACGGAATTAGTGAGCACTTTGTCCAGGAAGCTGGCTCCGCCCCTTGTGACGTTACTGAGTGCTGAGCCCGAAGTCCAATACGTAGCGCTACGGAACATAAACCTTGTGGTGCAGAAGAGACCGGATATATTAAAACACGAGATGAAGGTATTCTTCGTGAAGTACAACGATCCAATCTACGTGAAACTGGAAAAGCTGGATATCATGATACGTCTGGCGTCTCAAGCGAACATCGCGCAGGTCCTGGGCGAGCTGAAGGAGTACGCCACGGAGGTGGATGTGGATTTCGTGAGGAAGGCCGTCAGGGCCATAGGACGGTGTGCCATTAAGGTGGAGCCTTCAGCGGAGCGTTGCGTGTCAACCTTACTGGAATTAATTCAAACCAAAGTGAACTACGTGGTACAAGAGGCGATCGTTGTCATAAAGGACATATTCCGTAAATATCCCAACAAATACGAGAGCATTATAAGTACGTTGTGTGAAAATTTGGACACACTCGACGAGCCTGAGGCGAGAGCATCAATGGTTTGGATCGTGGGCGAGTACGCTGAGAGGATTGACAACGCCGACGAGCTCCTCGACTCTTTCCTCGAAGGTTTTCACGATGAGAACGCCCAGGTCCAGTTGCAGCTGTTAACAGCTGTTGTGAAGCTGTTCCTGAAGCGTCCAGCTGACACCCAGGAGCTCGTGCAGCATGTATTGAGTCTAGCCACACAGGACTCGGACAATCCAGATCTCAGGGACCGCGGGTTCATCTACTGGCGTCTGCTGTCAACGGATCCGGCTGCGGCTAAGGAGGTGGTCTTGGCTGATAAGCCTCTGATCTCTGAAGAAACGGACCTCTTGGAGCCGACCTTGCTAGACGAACTCATCTGCCACATAAGCTCGCTGGCGTCTGTGTACCACAAACCACCTACAGCATTCGTCGAAGGTCGCGGCGCTCCACAGGCGTTCTCAGATGGTCGAGCGCCACACACCGCGGACGAGGCGCCCGCGTCTGCGCCCGCTGTTATACCAAACCAGGAGTCCCTGATCGGTGATCTACTGTCTATGGATATCGGGGCCCCGCCTGCAGCGGCGACCGCGCCAGCACTCGACTTACTGGCTGGAGGGCTGGACGTACTTCTGGGCGGTCCTGCCGACAGCCAGCCGACAGCCAGCGTCTCTGGTAGCGCGACCGGTTTACTCGGAGACATCTTCGGAGCGACAGCACCCGCCTCATACGTACCACCCAAGCAATGTTGGCTGCCGGCTGATAAGGGAAAAGGTCTGGAGATTTGGGGTACATTCAGTCGCCAGAACGGTCAGCTTCGCATGGAGATGACGTTCACTAACAAAGCCATGCAGGCTATGAGCGGGTTCGCCATACAACTCAATAAGAATAGTTTCGGCGTGTACCCTGGAGGCGCGCTGTCTGTTGGAGCGCTCGGGGCGGAGGGGCGGGGGCGCGAGCTGACGCGCCTCTACCTCTGGCTACAGGCGGACCCGTTCAACGTGGCTGTCAAAAACAATATAGACGTATTTTACTTCGCGTGTCTCATTCCCGTTCACATCCTGTTCACTGAGGACGGACAGCTGGACAAGCGAGTGTTCCTCACCACCTGGAAGGAAATCCCAGCTGCGAACGAGTTCCAGCACACCATAACGAACGTCGTTGGCACCGCCGATTCGATCGCACAGAAAATGACCCTCAACAATGTTTTCACCATCGCTAAGAGGAACGTCGAGGGTCAAGACATGTTGTACCAGTCCCTCAAACTGACAAACAATATATGGGTCCTTCTAGAACTGAAGCTGCAACCCGGCAACCCAGAGGCCACGCTGAGCCTCAAGTCCCGCACCGTAGAGGTCGCTAATTGCATTTTCCAAGCTTACGAAGCCATCATTAAATCGTAA
>DPOGS207002-PA
MTDSKYFTTTKKGEIFELKSELNSDKKEKKKEAVKKVIASMTVGKDVSALFPDVVNCMQTDNLELKKLVYLYLMNYAKSQPDMAIMAVNTFVKDCEDSNPLIRALAVRTMGCIRVDKITEYLCEPLRKCLKDEDPYVRKTAAVCVAKLYDISPSMVEDQGFLDQLKDLLSDSNPMVVANAVAALSEINEASVSGHPLVEMNAPTINKLLTALNECTEWGQVFILDALSNYSPRDSREAHSICERITPRLAHANAAVVLSAVKVLMKLMEMLSDETELVSTLSRKLAPPLVTLLSAEPEVQYVALRNINLVVQKRPDILKHEMKVFFVKYNDPIYVKLEKLDIMIRLASQANIAQVLGELKEYATEVDVDFVRKAVRAIGRCAIKVEPSAERCVSTLLELIQTKVNYVVQEAIVVIKDIFRKYPNKYESIISTLCENLDTLDEPEARASMVWIVGEYAERIDNADELLDSFLEGFHDENAQVQLQLLTAVVKLFLKRPADTQELVQHVLSLATQDSDNPDLRDRGFIYWRLLSTDPAAAKEVVLADKPLISEETDLLEPTLLDELICHISSLASVYHKPPTAFVEGRGAPQAFSDGRAPHTADEAPASAPAVIPNQESLIGDLLSMDIGAPPAAATAPALDLLAGGLDVLLGGPADSQPTASVSGSATGLLGDIFGATAPASYVPPKQCWLPADKGKGLEIWGTFSRQNGQLRMEMTFTNKAMQAMSGFAIQLNKNSFGVYPGGALSVGALGAEGRGRELTRLYLWLQADPFNVAVKNNIDVFYFACLIPVHILFTEDGQLDKRVFLTTWKEIPAANEFQHTITNVVGTADSIAQKMTLNNVFTIAKRNVEGQDMLYQSLKLTNNIWVLLELKLQPGNPEATLSLKSRTVEVANCIFQAYEAIIKS-