| DPOGS207041 | ||
|---|---|---|
| Transcript | DPOGS207041-TA | 831 bp |
| Protein | DPOGS207041-PA | 276 aa |
| Genomic position | DPSCF300001 + 1795816-1797202 | |
| RNAseq coverage | 200x (Rank: top 47%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL006857 | 8e-150 | 87.68% | |
| Bombyx | BGIBMGA012982-TA | 3e-126 | 81.89% | |
| Drosophila | CG10903-PA | 9e-113 | 67.63% | |
| EBI UniRef50 | UniRef50_Q9CY21 | 4e-100 | 61.37% | Uncharacterized methyltransferase WBSCR22 n=190 Tax=root RepID=WBS22_MOUSE |
| NCBI RefSeq | XP_972432.2 | 1e-125 | 75.46% | PREDICTED: similar to CG10903 CG10903-PA [Tribolium castaneum] |
| NCBI nr blastp | gi|189238660 | 2e-124 | 75.46% | PREDICTED: similar to CG10903 CG10903-PA [Tribolium castaneum] |
| NCBI nr blastx | gi|189238660 | 3e-119 | 75.46% | PREDICTED: similar to CG10903 CG10903-PA [Tribolium castaneum] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0008152 | 2.2e-11 | metabolic process | |
| GO:0008168 | 2.2e-11 | methyltransferase activity | ||
| KEGG pathway | mdo:100018676 | 2e-105 | ||
| K00599 (E2.1.1.-) | maps-> | Naphthalene and anthracene degradation | ||
| Tyrosine metabolism | ||||
| Histidine metabolism | ||||
| Selenoamino acid metabolism | ||||
| InterPro domain | [201-275] IPR022238 | 2.8e-18 | Uncharacterised protein family, methyltransferase, Williams-Beuren syndrome | |
| [55-128] IPR013216 | 2.2e-11 | Methyltransferase type 11 | ||
| Orthology group | MCL15223 | Single-copy universal gene | ||
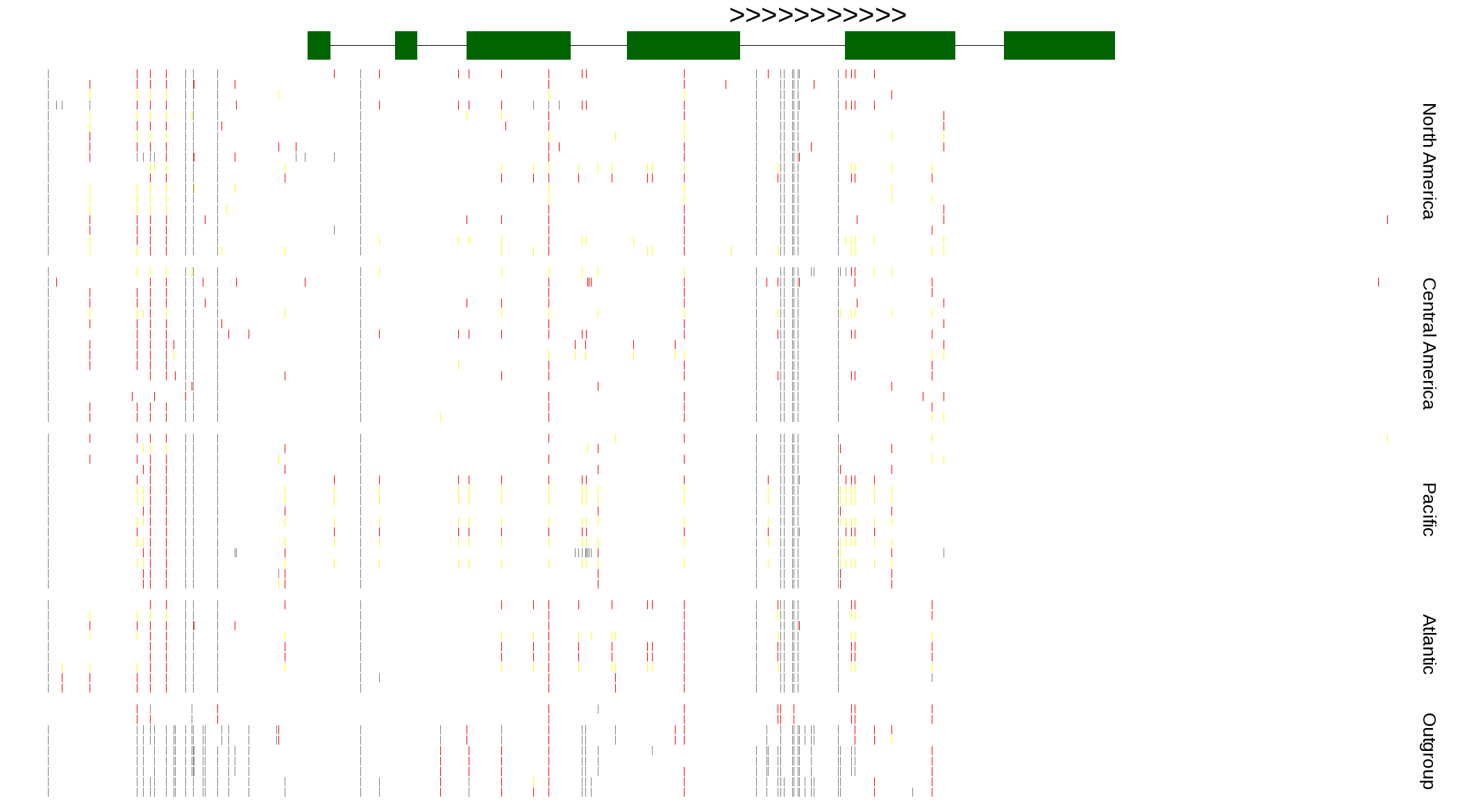
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS207041-TA
ATGGCTCGAAGACCAGAACATCAAGCACCACCCGAAATTTTTTATAATGAAGATGAAGCGAGAAAGTATACACAAAACACTAGGATCATAGACATTCAGGGGCAGATGACTGAAAGATGCATAGAATTATTGATACTCCCTGAAGATACCCCATGTTTGCTGTTGGATATTGGATGTGGATCAGGCTTATCCGGAACTGTATTAGAAGAAAATGGACATATGTGGATTGGATTAGACATTTCCCCTGCCATGTTAGATGTAGCTTTAGAGAGGGAGACCGAGGGTGACCTCATTCTTTCAGACATGGGTCAAGGAGTGCCATTTAAGGCTGGCAGCTTTGATGGTGCAGTCTCCGTGTCTGCTATACAGTGGCTGTTTAATGCAGACAAAAAATCACACAATCCAGTCAAAAGACTTTATAATTTCTTCAGTTCTTTATATGCCTCACTGTCAAGGTCAGCAAGGGCAGTGTTTCAATTTTACCCTGAAAATGAGAGTCAGTTAGATCTGTTAACATCTCAAGCCATGAAGGCAGGTTTCTATGGAGGAGTTGTTGTTGATTACCCTAACTCGGCTAAGGCGAAGAAATTCTTCTTAGTGTTAATGACGGGAGGTGCAGCACCTTTGCCTCAAGCTCTTGGTACAGATGAAAGTAATAATTCATTACAAGTTAAATATGCTAAAAGGGAAGCCATGAGAGCTGCAAGAGGGAAACCTTTAAAAAATACTAAAGCTTGGTTACTAGAGAAAAAGGAAAGGAGAAGGAAACAGGGCAAGGATACGAAACCTGATACTAAATACACTGGAAGGAAGAGAAGTGGAAGATTCTGA
>DPOGS207041-PA
MARRPEHQAPPEIFYNEDEARKYTQNTRIIDIQGQMTERCIELLILPEDTPCLLLDIGCGSGLSGTVLEENGHMWIGLDISPAMLDVALERETEGDLILSDMGQGVPFKAGSFDGAVSVSAIQWLFNADKKSHNPVKRLYNFFSSLYASLSRSARAVFQFYPENESQLDLLTSQAMKAGFYGGVVVDYPNSAKAKKFFLVLMTGGAAPLPQALGTDESNNSLQVKYAKREAMRAARGKPLKNTKAWLLEKKERRRKQGKDTKPDTKYTGRKRSGRF-