| DPOGS207425 | ||
|---|---|---|
| Transcript | DPOGS207425-TA | 786 bp |
| Protein | DPOGS207425-PA | 261 aa |
| Genomic position | DPSCF300087 + 369013-372221 | |
| RNAseq coverage | 1961x (Rank: top 6%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL014909 | 3e-99 | 77.34% | |
| Bombyx | BGIBMGA007144-TA | 2e-08 | 24.51% | |
| Drosophila | CG4747-PB | 7e-85 | 55.34% | |
| EBI UniRef50 | UniRef50_Q7Q161 | 8e-96 | 64.43% | Putative oxidoreductase GLYR1 homolog n=17 Tax=Arthropoda RepID=GLYR1_ANOGA |
| NCBI RefSeq | XP_002426591.1 | 2e-98 | 72.61% | 2-hydroxy-3-oxopropionate reductase, putative [Pediculus humanus corporis] |
| NCBI nr blastp | gi|322796122 | 2e-98 | 70.36% | hypothetical protein SINV_02941 [Solenopsis invicta] |
| NCBI nr blastx | gi|322796122 | 1e-94 | 70.36% | hypothetical protein SINV_02941 [Solenopsis invicta] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0055114 | 1.3e-128 | oxidation-reduction process | |
| GO:0016491 | 1.3e-128 | oxidoreductase activity | ||
| GO:0016616 | 6.5e-25 | oxidoreductase activity, acting on the CH-OH group of donors, NAD or NADP as acceptor | ||
| GO:0050662 | 6.5e-25 | coenzyme binding | ||
| GO:0005488 | 5.9e-24 | binding | ||
| GO:0006098 | 2.3e-21 | pentose-phosphate shunt | ||
| GO:0004616 | 2.3e-21 | phosphogluconate dehydrogenase (decarboxylating) activity | ||
| KEGG pathway | cqu:CpipJ_CPIJ000400 | 4e-97 | ||
| K00020 (E1.1.1.31, mmsB) | maps-> | Valine, leucine and isoleucine degradation | ||
| InterPro domain | [9-256] IPR015815 | 1.3e-128 | 3-hydroxyacid dehydrogenase/reductase | |
| [139-256] IPR013328 | 6.5e-25 | Dehydrogenase, multihelical | ||
| [9-136] IPR016040 | 5.9e-24 | NAD(P)-binding domain | ||
| [137-260] IPR008927 | 5.2e-23 | 6-phosphogluconate dehydrogenase, C-terminal-like | ||
| [9-135] IPR006115 | 2.3e-21 | 6-phosphogluconate dehydrogenase, NADP-binding | ||
| Orthology group | MCL14560 | Multiple-copy universal gene | ||
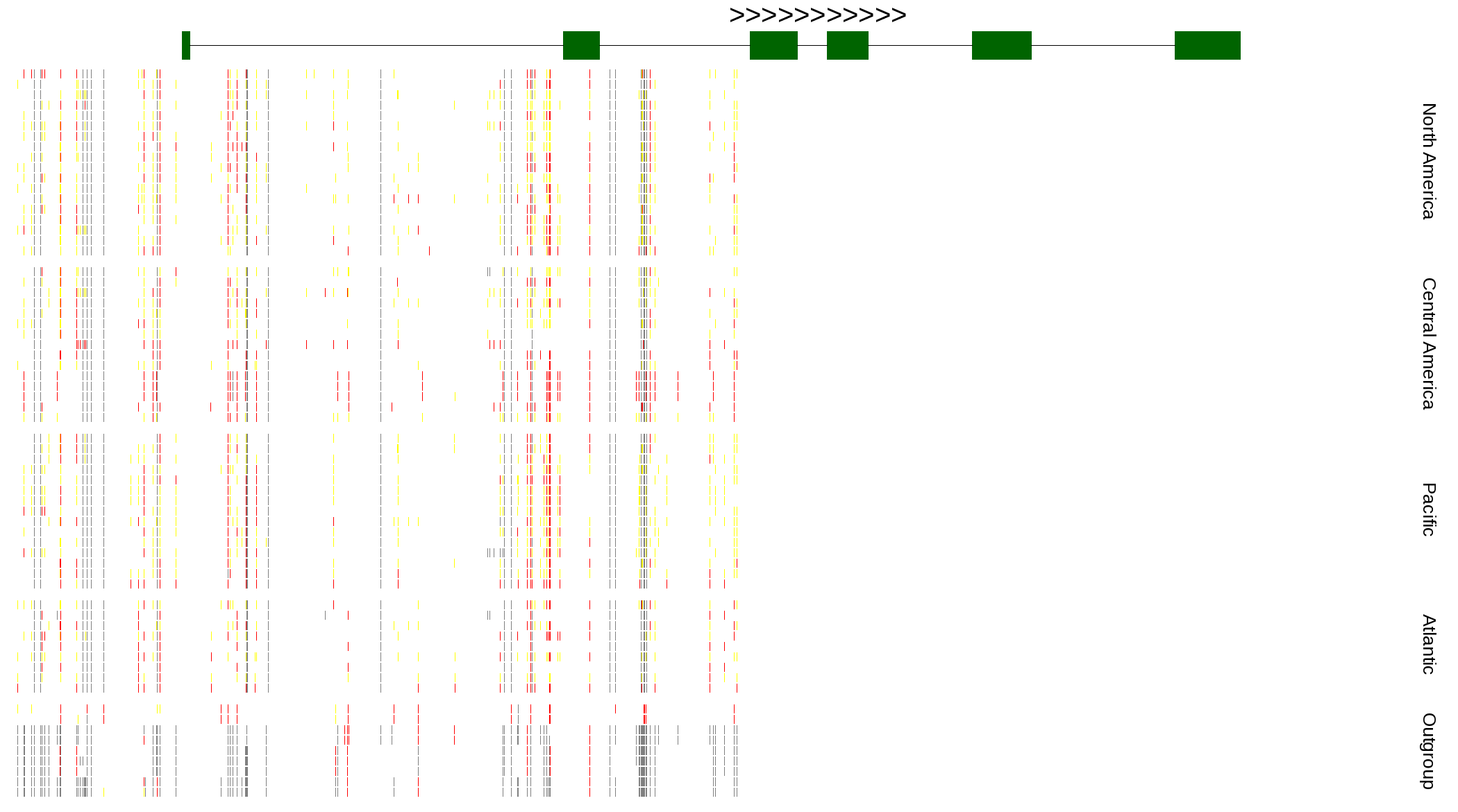
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS207425-TA
ATGTATGTTCCATATTGCCTAACTTGTAAAGACTTCGAGAAAGTCGGTGCTACGATCGCTGTGACTCCCTGCGATGTGGTGGAAGAGGCTGACATCACCTTCTCTTGCGTAGCGGACCCTCAGGCGGCCAAAGAGATGGTGTTCGGCAACTGCGGAGTGCTGCACTGTCCCACCCTGGAGGGCAAGGGCTACGTGGAGATGACCTCCATAGACGCCGACACCTCACACGACATAGTGGAGGCGCTCGGGGGAAAGGGAGGGAGATATCTGGAAGCACAGATCCAAGGCTCCAAGACCCAGGCGGAGGAGGGTACGCTCATCATCCTGGCGGCCGGGGACCGCTCGCTGTTCGACGACTGTCAGTCGTGCTTCAAGGCCATGAGCAAGAACTCCTTTTACCTCGGTAGTGAGATAGGCAACGCGTCCAAGATGAACTCGGTGCTGCAGGTGGTGGGCGGAGTGTCGCTGGGCGCGCTGGCCGAGGGCCTGGCGCTGGCGGACCGCGCAGGCCTCAGCCAGGCCGACCTCCTGGATGTGCTGGCGCTCACGCCGCTCGCCAGCCCGCACCTCATACTCAAGGGACGAGCCATGATCGAGTCGTCGTACTCGACCCACCAGCCGCTGAGCCACATGCAGAAGGACCTGAAGCTGGCGCTGGGGCTGGGAGACGCCCTGGAGCAGTCCCTGCCGCTCACCGCCACCACCAACGAGATCTTCAAGCACGCCAAGCGGCTCGGCTACGCCAACCATGACGTGGCCGCCGTCTACATCCGCGCCAGGTTCTAG
>DPOGS207425-PA
MYVPYCLTCKDFEKVGATIAVTPCDVVEEADITFSCVADPQAAKEMVFGNCGVLHCPTLEGKGYVEMTSIDADTSHDIVEALGGKGGRYLEAQIQGSKTQAEEGTLIILAAGDRSLFDDCQSCFKAMSKNSFYLGSEIGNASKMNSVLQVVGGVSLGALAEGLALADRAGLSQADLLDVLALTPLASPHLILKGRAMIESSYSTHQPLSHMQKDLKLALGLGDALEQSLPLTATTNEIFKHAKRLGYANHDVAAVYIRARF-