| DPOGS209534 | ||
|---|---|---|
| Transcript | DPOGS209534-TA | 921 bp |
| Protein | DPOGS209534-PA | 306 aa |
| Genomic position | DPSCF300157 - 2794-16434 | |
| RNAseq coverage | 0x (Rank: top 98%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL011581 | 5e-31 | 40.61% | |
| Bombyx | BGIBMGA013855-TA | 2e-105 | 77.10% | |
| Drosophila | Hr51-PC | 2e-64 | 56.28% | |
| EBI UniRef50 | UniRef50_D6WR05 | 3e-88 | 60.95% | Hormone receptor 51 n=7 Tax=Coelomata RepID=D6WR05_TRICA |
| NCBI RefSeq | XP_002423135.1 | 3e-86 | 53.87% | conserved hypothetical protein [Pediculus humanus corporis] |
| NCBI nr blastp | gi|270011038 | 1e-87 | 60.95% | hormone receptor 51 [Tribolium castaneum] |
| NCBI nr blastx | gi|270011038 | 4e-93 | 61.27% | hormone receptor 51 [Tribolium castaneum] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0003707 | 1.5e-55 | steroid hormone receptor activity | |
| GO:0005634 | 1.5e-55 | nucleus | ||
| GO:0006355 | 1.5e-55 | regulation of transcription, DNA-dependent | ||
| GO:0043401 | 1.5e-55 | steroid hormone mediated signaling pathway | ||
| GO:0003700 | 1.5e-55 | sequence-specific DNA binding transcription factor activity | ||
| GO:0003677 | 8e-21 | DNA binding | ||
| GO:0004879 | 4.9e-09 | ligand-dependent nuclear receptor activity | ||
| KEGG pathway | ||||
| InterPro domain | [59-306] IPR008946 | 1.5e-55 | Nuclear hormone receptor, ligand-binding | |
| [126-278] IPR000536 | 2.6e-29 | Nuclear hormone receptor, ligand-binding, core | ||
| [127-148] IPR001723 | 8e-21 | Steroid hormone receptor | ||
| [120-136] IPR003068 | 4.9e-09 | Transcription factor COUP | ||
| Orthology group | MCL12353 | Single-copy universal gene | ||
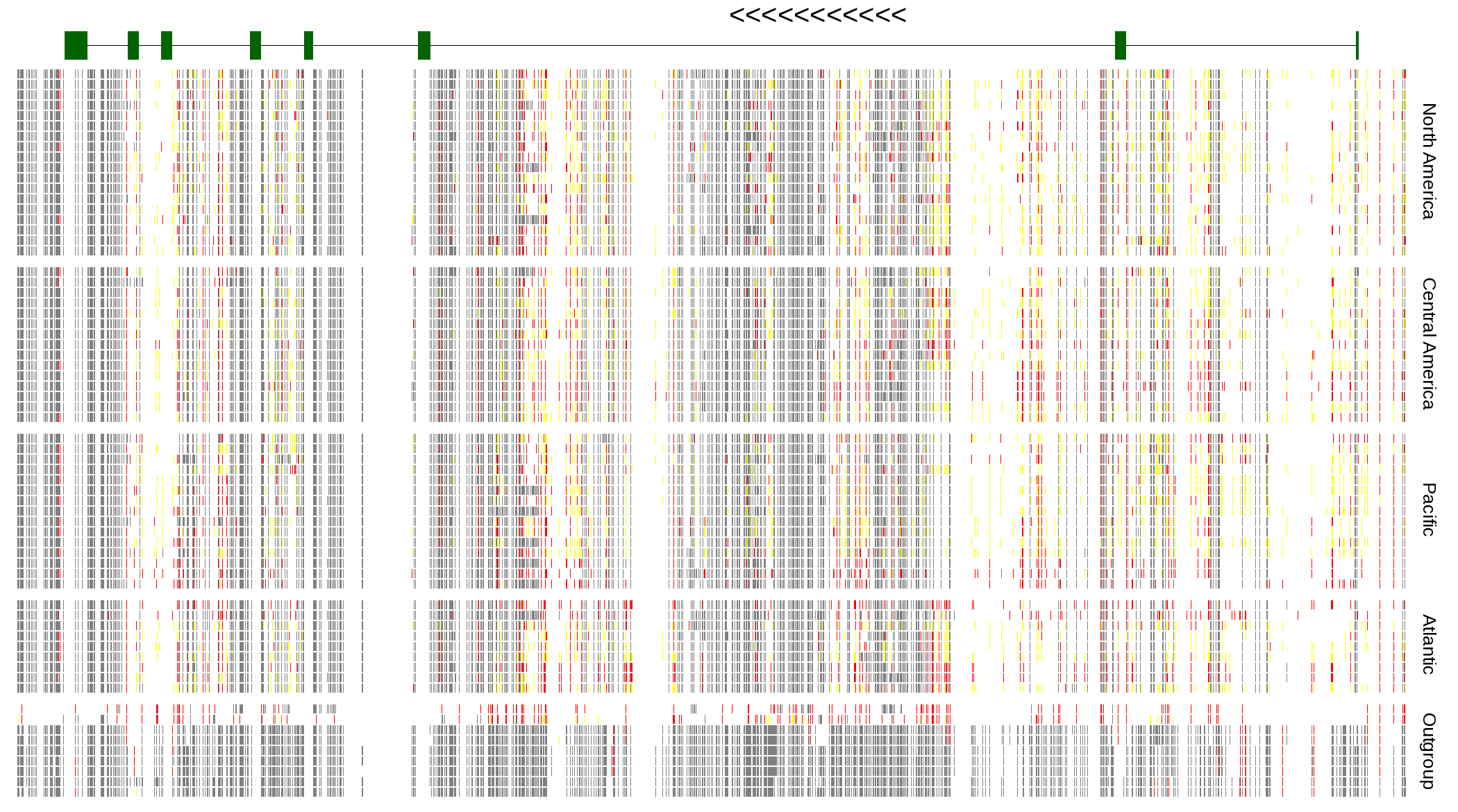
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS209534-TA
ATGTTGTTATTGAAAGGGTTAACTGTCCAGAACGAGCGTCAGCCACGGAACACCGCCACCATCAGGCCGGAGACGTTAAGGGATATGGACCAAGAAAGAGCTCTGAGAGAAGCCGCCGTCGCTGTCGGAGTATTTGGTCCGCCGGTGTCTCTGGCGATGGCCTTATCCCCGGCCAGATATCCTCTTCTGTCTCCACACTACGCCCCCCTGCCGCCACCGGATTCGACTCACGAACCAGAAAACCATCAAACGGACAGTGACGACGACAGTATTGACGTCACCAATGAAGAAGATTCTTCATCGTATTCTCCACCAGCGAACAGCTATCCACAGAACTGTATATCTTATGGGCCTCTGGGTATAGAGAGTGCTGCGGAAACAGCCGCCAGACTTCTGTTCATGGCGGTCAAGTGGGCGAGGAACCTGCCGTCATTCGCTGGACTGGCGTTCAGAGATCAGGTGACTCTATTAGAGGAGGGTTGGTCAGAGCTGTTCCTATTGAACGCTGTCCAGTGGTGCGCTCCACTAGACGCCGCAGCCAGCGCCCTCTTTGGAACAGAACACGACACCGGTGCTGGCGAGTGTCGGCGCCGTCTCCGCGCGGTGGTCTCTCGCTACCGTTCAGTCTTAGTTGATCCCGCGGAGTTCGCGTGTATGAAGGCCATCGTGCTCTTCAAACCTGAAACCCGAGGTCTAAAAGACCCCCTCCAGATCGAAAACCTTCAAGATCAAGCTCAAGTGATGCTAATGACTCACACAAGGACAGCTCACGGCACGGCCCCCGCTCGGTTCGGGAGGCTCCTACTTCTTCTACCACTCCTCCGCCTCGTCACGCCACAGCAATTGGAGAAGGAGTTCTTCGCGAAAACCATTGGAGAAACACCCATGGAAAAAGTACTCGCTGATATGTATAAGAATTAA
>DPOGS209534-PA
MLLLKGLTVQNERQPRNTATIRPETLRDMDQERALREAAVAVGVFGPPVSLAMALSPARYPLLSPHYAPLPPPDSTHEPENHQTDSDDDSIDVTNEEDSSSYSPPANSYPQNCISYGPLGIESAAETAARLLFMAVKWARNLPSFAGLAFRDQVTLLEEGWSELFLLNAVQWCAPLDAAASALFGTEHDTGAGECRRRLRAVVSRYRSVLVDPAEFACMKAIVLFKPETRGLKDPLQIENLQDQAQVMLMTHTRTAHGTAPARFGRLLLLLPLLRLVTPQQLEKEFFAKTIGETPMEKVLADMYKN-