| DPOGS209900 | ||
|---|---|---|
| Transcript | DPOGS209900-TA | 801 bp |
| Protein | DPOGS209900-PA | 266 aa |
| Genomic position | DPSCF300049 + 395600-396400 | |
| RNAseq coverage | 1774x (Rank: top 7%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL006751 | 1e-140 | 89.47% | |
| Bombyx | BGIBMGA014483-TA | 1e-134 | 84.53% | |
| Drosophila | CG12079-PA | 4e-103 | 76.65% | |
| EBI UniRef50 | UniRef50_O75489 | 4e-87 | 65.82% | NADH dehydrogenase [ubiquinone] iron-sulfur protein 3, mitochondrial n=131 Tax=cellular organisms RepID=NDUS3_HUMAN |
| NCBI RefSeq | XP_316497.2 | 9e-107 | 72.48% | AGAP006456-PA [Anopheles gambiae str. PEST] |
| NCBI nr blastp | gi|58388728 | 2e-105 | 72.48% | AGAP006456-PA [Anopheles gambiae str. PEST] |
| NCBI nr blastx | gi|58388728 | 4e-103 | 78.60% | AGAP006456-PA [Anopheles gambiae str. PEST] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0016651 | 7.8e-42 | oxidoreductase activity, acting on NADH or NADPH | |
| GO:0055114 | 7.8e-42 | oxidation-reduction process | ||
| GO:0008137 | 7.5e-32 | NADH dehydrogenase (ubiquinone) activity | ||
| KEGG pathway | aga:AgaP_AGAP006456 | 3e-106 | ||
| K03936 (NDUFS3) | maps-> | Huntington's disease | ||
| Oxidative phosphorylation | ||||
| Alzheimer's disease | ||||
| Parkinson's disease | ||||
| InterPro domain | [89-206] IPR010218 | 7.8e-42 | NADH dehydrogenase, subunit C | |
| [97-201] IPR001268 | 7.5e-32 | NADH:ubiquinone oxidoreductase, 30kDa subunit | ||
| Orthology group | MCL12867 | Single-copy universal gene | ||
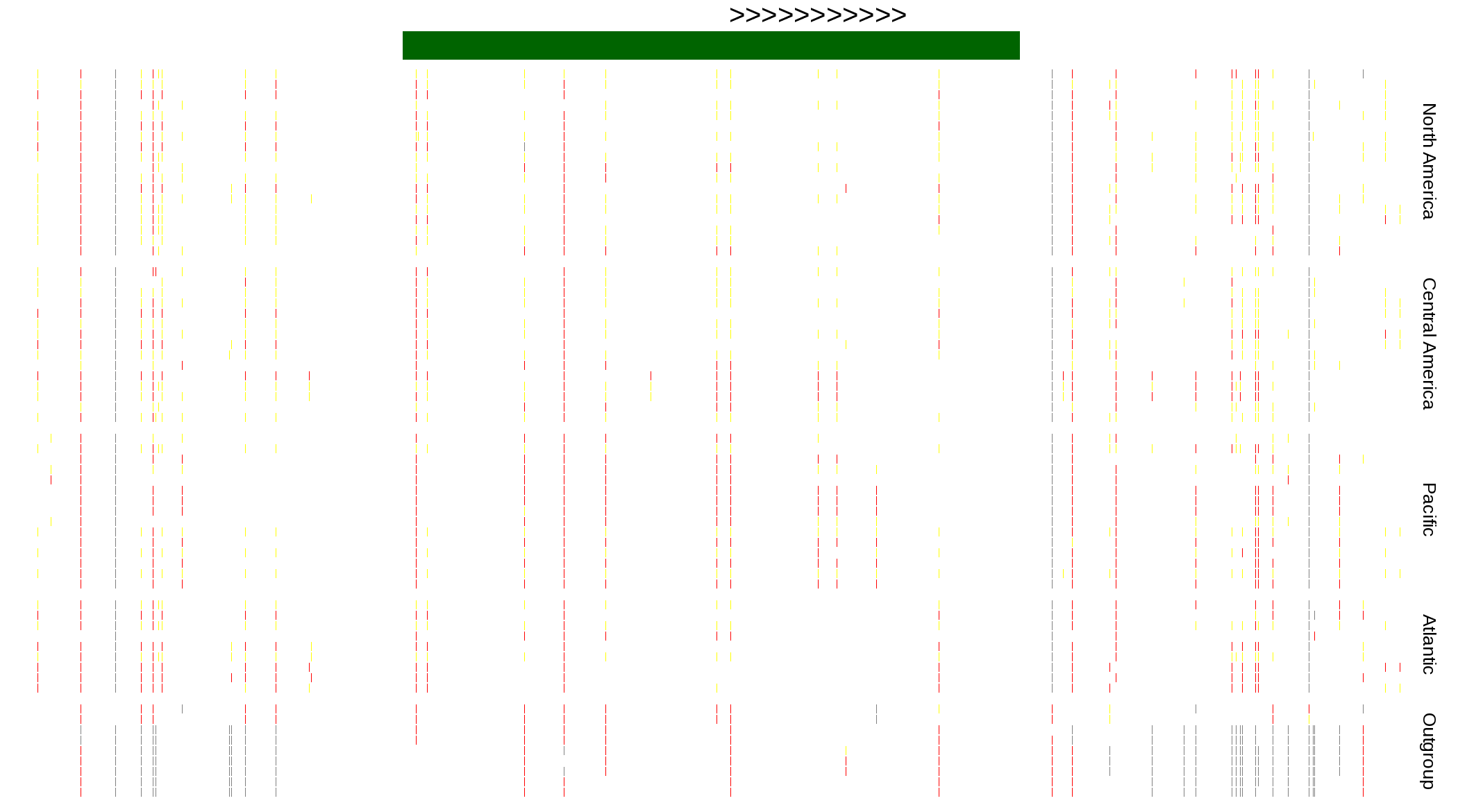
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS209900-TA
ATGTCTTTCTTTCTAAAACGCACCATTGGTGCAGGACGTAAACTAAGTCGGGCAATTTTGAATAATAACCAATACCCTGGTCTTCAACTTGTAGCAACAAAAACTGACCAAGTTCAACCTCAAGTCGAAACGCGACCGACTGTTGCCAAATTTGATCCATTGCAAAAAGCTCACCTAGTAGATTTTGGCAAATATGTAGCTGAATGCCTACCTAAATTCGTGCAGAAAGTTCAAATTACTGCAGGTAACGAACTTGAAGTTCTGGTGCCGACAGATGGTGTCATCCCTGTGCTTCAATTCCTTAAGGATCATCACAATGCACAGTTCGCAAATCTCGTGGATATTGGTGGCATGGATGTGCCTAGCCGACCCTACAGGTTCGAAATTATCTACAACCTACTGTCACTGCGCTACAATGCTCGAATCCGTGTGAAAACCTACACTGATGAACTGACACCAATCGATTCAGCTTGCGAAGTGTTCAAAGCTGCCAACTGGTATGAAAGAGAGATTTGGGACATGTACGGTGTCTTCTTCGCTAACCACCCAGACTTGAGAAGAATTTTAACTGACTACGGTTTTGAGGGTCACCCGTTCAGAAAGGACTTCCCCCTCAGTGGATATGTAGAATTGCGTTATGATGATGAACAGAAAAGGGTTGTGGTTGAACCATTGGAACTGGCCCAGGAGTTTAGGCGCTTCGAGTTAAGTGCACCCTGGGAGCAGTTCCCAAACTTCAGAGGAAATCCTGTGTCTGAGGATGTCGTAGATAAAACTGATGACCAACCCAAGAAAGAATAG
>DPOGS209900-PA
MSFFLKRTIGAGRKLSRAILNNNQYPGLQLVATKTDQVQPQVETRPTVAKFDPLQKAHLVDFGKYVAECLPKFVQKVQITAGNELEVLVPTDGVIPVLQFLKDHHNAQFANLVDIGGMDVPSRPYRFEIIYNLLSLRYNARIRVKTYTDELTPIDSACEVFKAANWYEREIWDMYGVFFANHPDLRRILTDYGFEGHPFRKDFPLSGYVELRYDDEQKRVVVEPLELAQEFRRFELSAPWEQFPNFRGNPVSEDVVDKTDDQPKKE-