| DPOGS210060 | ||
|---|---|---|
| Transcript | DPOGS210060-TA | 6177 bp |
| Protein | DPOGS210060-PA | 2058 aa |
| Genomic position | DPSCF300017 - 820857-851884 | |
| RNAseq coverage | 1489x (Rank: top 9%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL002983 | 0.0 | 76.61% | |
| Bombyx | BGIBMGA012701-TA | 0.0 | 85.55% | |
| Drosophila | CG9674-PF | 0.0 | 69.82% | |
| EBI UniRef50 | UniRef50_E5SC90 | 0.0 | 55.42% | Glutamate synthase n=2 Tax=cellular organisms RepID=E5SC90_TRISP |
| NCBI RefSeq | NP_001041678.1 | 0.0 | 84.89% | glutamate synthase [Bombyx mori] |
| NCBI nr blastp | gi|115292419 | 0.0 | 84.89% | glutamate synthase [Bombyx mori] |
| NCBI nr blastx | gi|115292419 | 0.0 | 84.89% | glutamate synthase [Bombyx mori] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0045181 | 0 | glutamate synthase activity, NADH or NADPH as acceptor | |
| GO:0005506 | 0 | iron ion binding | ||
| GO:0050660 | 0 | flavin adenine dinucleotide binding | ||
| GO:0016040 | 0 | glutamate synthase (NADH) activity | ||
| GO:0010181 | 0 | FMN binding | ||
| GO:0006537 | 1.8e-187 | glutamate biosynthetic process | ||
| GO:0055114 | 1.8e-187 | oxidation-reduction process | ||
| GO:0016639 | 1.8e-187 | oxidoreductase activity, acting on the CH-NH2 group of donors, NAD or NADP as acceptor | ||
| GO:0008152 | 4.2e-187 | metabolic process | ||
| GO:0003824 | 4.2e-187 | catalytic activity | ||
| GO:0015930 | 2e-153 | glutamate synthase activity | ||
| GO:0016638 | 2e-153 | oxidoreductase activity, acting on the CH-NH2 group of donors | ||
| GO:0006807 | 4.5e-112 | nitrogen compound metabolic process | ||
| GO:0016491 | 2.3e-110 | oxidoreductase activity | ||
| GO:0051536 | 7.9e-39 | iron-sulfur cluster binding | ||
| KEGG pathway | tca:658584 | 0.0 | ||
| K00264 (GLT1) | maps-> | Nitrogen metabolism | ||
| Alanine, aspartate and glutamate metabolism | ||||
| InterPro domain | [1-2055] IPR012220 | 0 | Glutamate synthase, eukaryotic | |
| [1575-2000] IPR006005 | 1.8e-187 | Glutamate synthase, NADH/NADPH, small subunit 1 | ||
| [831-1256] IPR013785 | 4.2e-187 | Aldolase-type TIM barrel | ||
| [845-1212] IPR002932 | 2e-153 | Glutamate synthase, central-C | ||
| [21-415] IPR000583 | 5.6e-127 | Glutamine amidotransferase, class-II | ||
| [500-785] IPR006982 | 4.5e-112 | Glutamate synthase, central-N | ||
| [1269-1537] IPR002489 | 2.3e-110 | Glutamate synthase, alpha subunit, C-terminal | ||
| [1575-1720] IPR012285 | 7.9e-39 | Fumarate reductase, C-terminal | ||
| [1575-1729] IPR009051 | 2.3e-38 | Alpha-helical ferredoxin | ||
| [1721-1917] IPR023753 | 4.6e-13 | Pyridine nucleotide-disulphide oxidoreductase, FAD/NAD(P)-binding domain | ||
| Orthology group | MCL15997 | Insect specific | ||
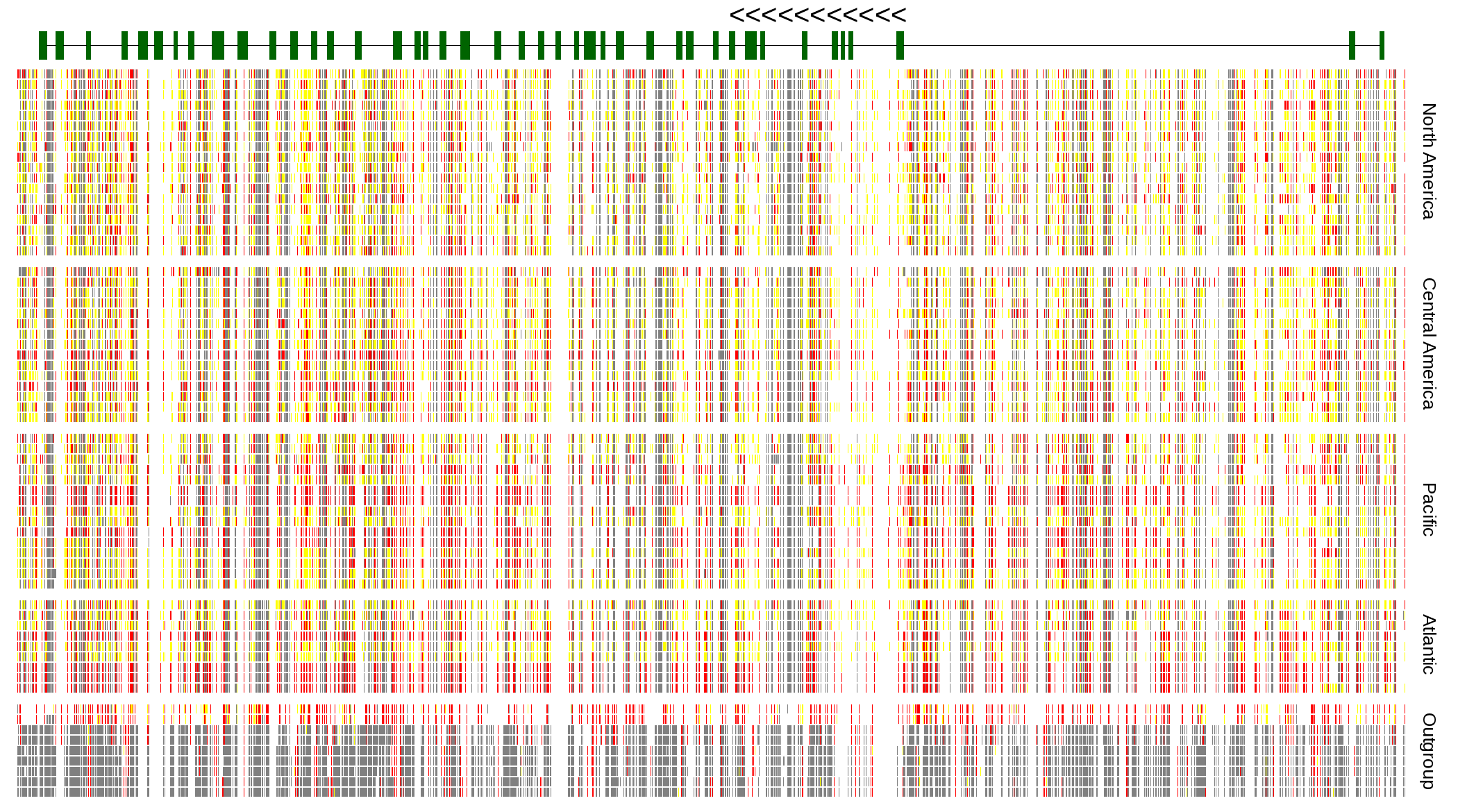
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS210060-TA
ATGGAGTGGGAAGCACCACCCAAGCAAGGCTTGTACGACCCCCAAAACGAGCACGAGGCTTGCGGTGTTGGATTTGTTGTTGCTATCGACGGAAAACGTTCTCATAAGATCGTTCGCGATGCCGAAGTCCTCGCAAAGCGCATGGAACACCGTGGAGCGTGCGCCTGTGACAATGACACCGGCGATGGCGCTGGTGTGTTGACCGCCATCCCTCACCAGTTCTACTGCGCTCAGCTAAGAGACAGCCACCAAATCGATTTACCCCCGTTCGGGAAGTACGCCACCGGCATCTTCTTCCTGGACAAGCTTCACCATCAGGACATCGAGAAGAAGTTCCAGGAGTTAGCTGAGAGCCTCCACCTCCGCGTGATCTGCTGGAGGACTGTACCAACCAATAACGCCACTATCGGTCAAGTGGCTCGTAACTCGGAGCCGTATATGCGCCAAGTGTTTGTTACCGGAGATATCGGGGATGAACCTCAGCTAGCTCGTCAGCGACCCAGGATAGAAGGCACTCTTGAAGCATTTTTTTCAGATCGCCGTCGCTCGCCGGCCGCCGCTCCGCCGCCACTCGTCCACATCTTCGTGTTACGCAAGCGCGCCTCCCACGAGCTGGTGGTGCCGGGAGCCCGCTTCTATATTTGCAGCTTATCTCTGAGGACCGTCGTTTACAAGGGACTCCTCACATCCAATCAGCTATGGGAATACTTCAAGGATCTGAGCAACCCGGCGTTCACTACATACCTGGCGCTGGTCCACACTCGCTTCTCAACCAACACCTTCCCCAGCTGGGAGAGAGCCCATCCTTTGAGAGTGCTTGCCCACAATGGAGAAATAAATACATTACGAGGTAACGTCAACCTGATGAAGGCCCGGGAAGGTGTCATGAAGAGTGATATATTTGGAGATGAACTAAAGAAGCTGTACCCGGTGGTGGAACCCAACTTATCTGACTCCGGCTCAGCCGATTGTGTGCTGGAGTTCCTCCTGCACTGCGGTCATAGATCTTTGCCGGAAGCTGTCATGACTATGGTACCGGAAGCATGGCATAATGACGTCACCATGCCCGCAGAAAAGAGGGATTACTACCAATGGGCAGCTTGTGCCATGGAGCCATGGGATGGGCCAGCTCTAGTGTCCTTTACTGATGGAAGATATATTGGCGCCATTCTGGACAGAAATGGTCTGAGACCATCCAGGTTCTATGTCACGAGTGAGAACATTCTCGTGATGGCCTCGGAGGTGGGAGTCTATGATGTGGATCCGGAGAAGGTTATCCTCAAGAGTCGTCTGAAGCCAGGCCGCATGTTGTTAGTGGACACCGAGGAGAAGAGAATCATACAAGACGTGGAGCTGAAGATGGACATCGCCAGGAGCAGACCGCACTCACAGTGGCTCAAGGAGCAGATAACAATGGAGGATATTTACAAATCGGTGTCCCAGAGCGATTTGTCCAGTAATGGGTGTGTGAATGGAGCTATATCTGGTCTGGGGGACAAGAGGCTCGGTCTGTTTGGATACACCATAGAGTCCATCAACATGCTGCTACTGCCCATGATACAGAACAAGAAAGAGGCTCTCGGCAGCATGGGGAACGACGCGCCCCTGGCTTGTCTGTCTCGTTTCGAACCCCTGCCCTACGACTACTTCAAGCAGCTGTTCGCACAGGTCACCAACCCACCCATCGACCCCTTCCGTGAGAAGATCGTGATGTCCCTGATGTGTCCGATCGGCCCGGTGGCCAACATCCTGCGGCCCGGCGCGGAGTTCGTGCACCGCCTGTTCCTGCCGCAGCCCGTGCTGTCCATCCCGGACCTCAAGGCGCTGATCGCCACCACACATCGCGGCTGGAGGACGAAGGTTATCGATTGTACGTTCGATATATCCGACGGTCCCATGGGCCTGGAGCCGGCCCTGACTCGCCTGGCGGGGGAGGCGCATGACGCTGCTGAGGACGGCTACCAGCTGCTGGTGCTCTCCGACCGCCAGGCCGGGCCAACTAGGGTCCCGATCAGCTCGTTACTCGCCCTGGGTGCGGTCCATCACCACCTTATCGAGACCCGTCAGCGCATGAAGGTCGGGGTCCTCGTGGAGACGGCCGAGGCCAGGGAAGTCCATCACATGTGTGTCTTACTCGGTTATGGAGCCGACGCTATATGTCCCTACCTGGCCTTCGAACTAGCGTTCTCTCTTCGAAACGACAACCTCATAGATCCAAACTTAACGGACAGCGACATATACCTGGCGTACCAGAAGGCCATAGAGACGGGTCTGGCTAAAGTCATGGCCAAAATGGGCATCAGCATGCTGCAGTCGTACAAAAGCGCCCAGATATTCGAGGCGGTCGGCCTCAGCGAGGAAGTTATCGACAAATGCTTCAGAGGCACTCAGTCTAGAATCGGTGGGATTACCTTTGAGATTCTCTCTCAGGAGACTTTCGACCGACACGCCCTCACGTACGGCAACTGTAACGACATGCTGGTGCTACGTAACCCCGGCAACTACCACTGGAGGGCTGGCGGGGAGAAGCATATCAACGACCCGCTGTCCATCGCCAACCTTCAGGAGGCCGCCGTCAACAACACGGCTTCCGCCTACGACAGATTCAGAGAGAGCGCTCTGGAATCTATCCGCGCCTGTACACTCCGAGGTCAACTCGAGCTGGTCACCCTGGACGAACCCCTGCCGCTATCAGAGATAGAACCGGCTTCGGAGATAGTCAAGAGATTCGCTACTGGCGCGATGTCCTTCGGTTCAATATCTATGGAGGCTCACTCCACACTGGCCATCGCCATGAACAAGATCGGAGGAAAGTCCAACACCGGGGAGGGGGGAGAAACCGCTGAGAGATATCTCAACCAGGATCCAGACCACAACATGCGCTCGGCGATCAAGCAGGTGGCGTCCGGGAGGTTCGGAGTGACGGCGTCATACCTCGCACATGCTGACGACCTGCAGATTAAGATGGCGCAGGGAGCCAAGCCGGGGGAGGGCGGGGAACTACCCGGGTACAAAGTAACAGAGGAGATAGCTCGTACCCGTTGTTCAGTTCCGGGGGTAGGGCTGATCTCCCCGCCTCCTCACCATGATATATACTCCATCGAGGACCTCGCCGAGCTGATCTACGATCTCAAATGTGCCAACCCTAAAGCACGCATCAGTGTGAAACTGGTCTCGGAGGTTGGAGTGGGAGTAGTGGCTTCCGGTGTCGCTAAGGGTAAAGCGGAACACATCGTCATATCCGGCCACGACGGAGGCACTGGGGCCAGTTCCTGGACGGGCATCAAGAGCGCGGGGCTGCCCTGGGAGTTGGGCGTGGCGGAAACACACCAGGTGCTCGTATTGAACGACCTGAGGTCGCGTGTGGTGGTCCAAGCTGACGGTCAGATCCGCACCGGCTTCGACGTGATAGTGGCGGCGCTGCTGGGAGCTGACGAGGTCGGCTTCAGCACCGCGCCATTGATAGCGTTAGGCTGCACTATGATGAGGAAGTGTCACCTGAACACCTGTCCGGTTGGCATCGCGACTCAGGACCCCGTGTTGAGGAAGAAGTTCGCGGGGAAGCCGGAACACGTCATTAACTACCTGTTCATGTTGGCTGAGGAGGTCCGTACGCACATGTCACGCGTGGGTGTCCGGAGCTTCCAAGAGCTGGTCGGTCGGACAGACCTCCTGAAGGTGAGGGAGAAGAACGACAACTACAAAGCGCGGCTCCTCAACCTCGCTCCCATACTGAAGAACGCGTTACACATGAGGCCGGGCGTCGACATACGAGGCGGCTCTAAACCACAGGACTTCCAGCTGGAGAAACGCCTGGACAACCAGCTGATCCAGCAGTGCTCTGGAATACTGGACGGAACCCAACAACACGTACACATCGACATGAAGATCACTAACGAAGACCGAGCTTTCACTTCGACACTCTCCTATCATATTGCCATGCAGTATGGAGATTCCGGTCTCCCTGATGGCACCACGGTGGACATCAGCCTCACCGGCTCAGCCGGACAAAGCTTCTGTGCCTTCCTCAGCAAAGGAATCACCGTCACCTTGGAAGGAGACGCCAATGATTACGTCGGCAAGGGCCTCTCCGGCGGCACGGTCATCATCTACCCTCCAAAGAACTCTCCATTCCAATCTCACTTGAATGTGATCGTTGGGAACGTTTGTTTGTATGGAGCTACGAGTGGAAGGGCTTATTTCAGGGGTATAGCGTCTGAGCGTTTCTGTGTCCGTAACTCTGGTTGTGTGGCGGTGTCGGAGGGCGCGGGCGACCACGGCTGCGAGTACATGACGGCTGGCAGGGTGCTCATACTAGGACTGGTGGGGAGGAACTTCGCCGCGGGGATGAGCGGTGGTATAGCGTACGTGTACGACATCGATGGGTCATTCAAGAGCAAATGTAATCCGGAGATGGTGGAACTGCTGCCACTGGAAATACAAGAAGACTTGGACGAGGTGCAGAAACTTCTAGAAGAATTCGTGGAGTATACCGGATCATTAATCGCTAAAGAACTCCTAGAGACCTGGCCGGAACCAGCTAAGAAGTTCACGAAGGTGTTCCCTTACGAATACCAGCGCGCCTTGAAACAGATCGCTCTCAAGCAGACGGCGCCCAAGGTGGAAACTAACGGAAAGCTTGAAGAAAACGGAGTCGTCGATATAGAAGAAGCTGTCAGAAACGTGGAACAGGACAAGAAGAACCTGGAGAAGGTTCTAGATAAGACCAGAGGATTTATAAAGTATCCCCGCGAGACGTCAGTGTACCGGCCGGCTGAGAAGCGTCTCCGTGACTGGGAGGAGATCTACGACCAGTCGTCCGTGAGGCGCGGCCTGAGAGTGCAGGCTGCTCGCTGCATGGAGTGCGGGGTGCCGTTCTGTCAGAGCGGCCACGGCTGCCCTCTAGGGAACATCATACCCAAGTGGAACGATCTCGTGTACAGGGCCGACTGGAAACAAGCTCTGGCACAACTCTTGCAGACTAATAATTTCCCAGAGTTCACGGGTCGCGTGTGTCCCGCGCCGTGCGAGGGCGCCTGTGTGCTCGGCATCTCCGAACCTCCCGTCACCATCAAGAACATCGAGTGCGCCATCATTGACCACGCCTTCAGCAGCGGATGGGTTCAACCGGAGATCCCGGAGTATCGTAACGGTAAGACAGTCGCCATCGTGGGGTCGGGGCCGGCCGGCCTGGCCTGCGCTCATCAGCTAAACAAGGCCGGTTACTCTGTGACGGTGTTCGAGCGCAACGACCGTCCGGGCGGCCTGCTCCAGTACGGCATCCCCAGCATGAAGCTCAGCAAGCACGTGGTGCAGCGGAGGATCAAGCTCATGATGGACGAGGGGGTCGTGTTCAAGTGCAACGTGGACGTCGGCAAGGACATCTCCGCCGCGGACCTCGCCAACGAGTACGACGCGCTAGTCCTGTGTATGGGCGCGACGTGGCCGCGGGATCTCCCTCTGAGCGGCCGGCAGCTGGGCGGCATACACTTCGCCATGGAGTTCCTCGAGGGCTGGCAGAAGAAACAGGCGGGCGGCGGCACCGGCAAACTACCCGCGCTCAGCGCCAAGGACAAGAACGTACTCGTTATAGGGGGAGGGGACACCGGATGCGACTGTATAGCGACGTCTCTACGCCAGGGCGCCAAATCTATAACGACCTTCGAGATACTTCCCGAGCCCAAACCCACGCGGACCAAGGAGAACCCGTGGCCGCAGTGGCCGAGGGTCTTCCGAGTGGACTACGGCCATGAGGAGGTGAAAGTGAAATTCGGTCACGACCCTAGAAAATTCTCGACTCTCACCAAGGAGTTCCTCGACGATGGCGAGGGCAACGTGTCGGGGGTGAGTGCGGTGGAAGTGGAGTGGACGCGCGGTCCGGGCGGGAGGTGGGAGATGGCCGAGAAGGACGGCTCCAAGCGAGTCGTTCCGTGCGACCTGGTCCTCCTCGCCATGGGCTTCCTGGGACCTGAGAGATACGTCGCCTCGCAACTCGGGTGTATTGCAAAAATAAACAAAAAGCGCTTGCTTGGGAAATTTAATGAAAGAGCTATAATAAGATCAAGCAATACGAGAGCCGATAGTGCAGATCTACGTAAAGCAAATCCATACGTGGTAGCAACTTTCTTTGCGTGTGACCCTCACTCGCTCTTCGCAGTTTCGGAATGCAAAAACTAA
>DPOGS210060-PA
MEWEAPPKQGLYDPQNEHEACGVGFVVAIDGKRSHKIVRDAEVLAKRMEHRGACACDNDTGDGAGVLTAIPHQFYCAQLRDSHQIDLPPFGKYATGIFFLDKLHHQDIEKKFQELAESLHLRVICWRTVPTNNATIGQVARNSEPYMRQVFVTGDIGDEPQLARQRPRIEGTLEAFFSDRRRSPAAAPPPLVHIFVLRKRASHELVVPGARFYICSLSLRTVVYKGLLTSNQLWEYFKDLSNPAFTTYLALVHTRFSTNTFPSWERAHPLRVLAHNGEINTLRGNVNLMKAREGVMKSDIFGDELKKLYPVVEPNLSDSGSADCVLEFLLHCGHRSLPEAVMTMVPEAWHNDVTMPAEKRDYYQWAACAMEPWDGPALVSFTDGRYIGAILDRNGLRPSRFYVTSENILVMASEVGVYDVDPEKVILKSRLKPGRMLLVDTEEKRIIQDVELKMDIARSRPHSQWLKEQITMEDIYKSVSQSDLSSNGCVNGAISGLGDKRLGLFGYTIESINMLLLPMIQNKKEALGSMGNDAPLACLSRFEPLPYDYFKQLFAQVTNPPIDPFREKIVMSLMCPIGPVANILRPGAEFVHRLFLPQPVLSIPDLKALIATTHRGWRTKVIDCTFDISDGPMGLEPALTRLAGEAHDAAEDGYQLLVLSDRQAGPTRVPISSLLALGAVHHHLIETRQRMKVGVLVETAEAREVHHMCVLLGYGADAICPYLAFELAFSLRNDNLIDPNLTDSDIYLAYQKAIETGLAKVMAKMGISMLQSYKSAQIFEAVGLSEEVIDKCFRGTQSRIGGITFEILSQETFDRHALTYGNCNDMLVLRNPGNYHWRAGGEKHINDPLSIANLQEAAVNNTASAYDRFRESALESIRACTLRGQLELVTLDEPLPLSEIEPASEIVKRFATGAMSFGSISMEAHSTLAIAMNKIGGKSNTGEGGETAERYLNQDPDHNMRSAIKQVASGRFGVTASYLAHADDLQIKMAQGAKPGEGGELPGYKVTEEIARTRCSVPGVGLISPPPHHDIYSIEDLAELIYDLKCANPKARISVKLVSEVGVGVVASGVAKGKAEHIVISGHDGGTGASSWTGIKSAGLPWELGVAETHQVLVLNDLRSRVVVQADGQIRTGFDVIVAALLGADEVGFSTAPLIALGCTMMRKCHLNTCPVGIATQDPVLRKKFAGKPEHVINYLFMLAEEVRTHMSRVGVRSFQELVGRTDLLKVREKNDNYKARLLNLAPILKNALHMRPGVDIRGGSKPQDFQLEKRLDNQLIQQCSGILDGTQQHVHIDMKITNEDRAFTSTLSYHIAMQYGDSGLPDGTTVDISLTGSAGQSFCAFLSKGITVTLEGDANDYVGKGLSGGTVIIYPPKNSPFQSHLNVIVGNVCLYGATSGRAYFRGIASERFCVRNSGCVAVSEGAGDHGCEYMTAGRVLILGLVGRNFAAGMSGGIAYVYDIDGSFKSKCNPEMVELLPLEIQEDLDEVQKLLEEFVEYTGSLIAKELLETWPEPAKKFTKVFPYEYQRALKQIALKQTAPKVETNGKLEENGVVDIEEAVRNVEQDKKNLEKVLDKTRGFIKYPRETSVYRPAEKRLRDWEEIYDQSSVRRGLRVQAARCMECGVPFCQSGHGCPLGNIIPKWNDLVYRADWKQALAQLLQTNNFPEFTGRVCPAPCEGACVLGISEPPVTIKNIECAIIDHAFSSGWVQPEIPEYRNGKTVAIVGSGPAGLACAHQLNKAGYSVTVFERNDRPGGLLQYGIPSMKLSKHVVQRRIKLMMDEGVVFKCNVDVGKDISAADLANEYDALVLCMGATWPRDLPLSGRQLGGIHFAMEFLEGWQKKQAGGGTGKLPALSAKDKNVLVIGGGDTGCDCIATSLRQGAKSITTFEILPEPKPTRTKENPWPQWPRVFRVDYGHEEVKVKFGHDPRKFSTLTKEFLDDGEGNVSGVSAVEVEWTRGPGGRWEMAEKDGSKRVVPCDLVLLAMGFLGPERYVASQLGCIAKINKKRLLGKFNERAIIRSSNTRADSADLRKANPYVVATFFACDPHSLFAVSECKN-