| DPOGS210561 | ||
|---|---|---|
| Transcript | DPOGS210561-TA | 1017 bp |
| Protein | DPOGS210561-PA | 338 aa |
| Genomic position | DPSCF300304 + 184058-186287 | |
| RNAseq coverage | 270x (Rank: top 40%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL009554 | 5e-135 | 93.88% | |
| Bombyx | BGIBMGA013453-TA | 5e-133 | 87.92% | |
| Drosophila | cdc2c-PC | 7e-95 | 66.12% | |
| EBI UniRef50 | UniRef50_P24941 | 2e-105 | 69.14% | Cyclin-dependent kinase 2 n=105 Tax=Eukaryota RepID=CDK2_HUMAN |
| NCBI RefSeq | XP_393450.3 | 2e-105 | 68.60% | PREDICTED: similar to cyclin-dependent kinase 2 [Apis mellifera] |
| NCBI nr blastp | gi|378404922 | 3e-130 | 87.92% | cyclin dependent kinase 2 [Bombyx mori] |
| NCBI nr blastx | gi|378404922 | 3e-139 | 87.92% | cyclin dependent kinase 2 [Bombyx mori] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0016772 | 2.1e-82 | transferase activity, transferring phosphorus-containing groups | |
| GO:0005524 | 1.3e-79 | ATP binding | ||
| GO:0004674 | 1.3e-79 | protein serine/threonine kinase activity | ||
| GO:0006468 | 1.3e-79 | protein phosphorylation | ||
| GO:0004672 | 1.1e-66 | protein kinase activity | ||
| GO:0004713 | 7.3e-11 | protein tyrosine kinase activity | ||
| KEGG pathway | gga:429642 | 1e-106 | ||
| K02206 (CDK2) | maps-> | Small cell lung cancer | ||
| Pathways in cancer | ||||
| Prostate cancer | ||||
| p53 signaling pathway | ||||
| Progesterone-mediated oocyte maturation | ||||
| Cell cycle | ||||
| Oocyte meiosis | ||||
| InterPro domain | [2-269] IPR011009 | 2.1e-82 | Protein kinase-like domain | |
| [4-274] IPR002290 | 1.3e-79 | Serine/threonine-protein kinase domain | ||
| [5-227] IPR017442 | 1.1e-66 | Serine/threonine-protein kinase-like domain | ||
| [4-249] IPR020635 | 7.3e-11 | Tyrosine-protein kinase, catalytic domain | ||
| Orthology group | MCL11145 | Multiple-copy universal gene | ||
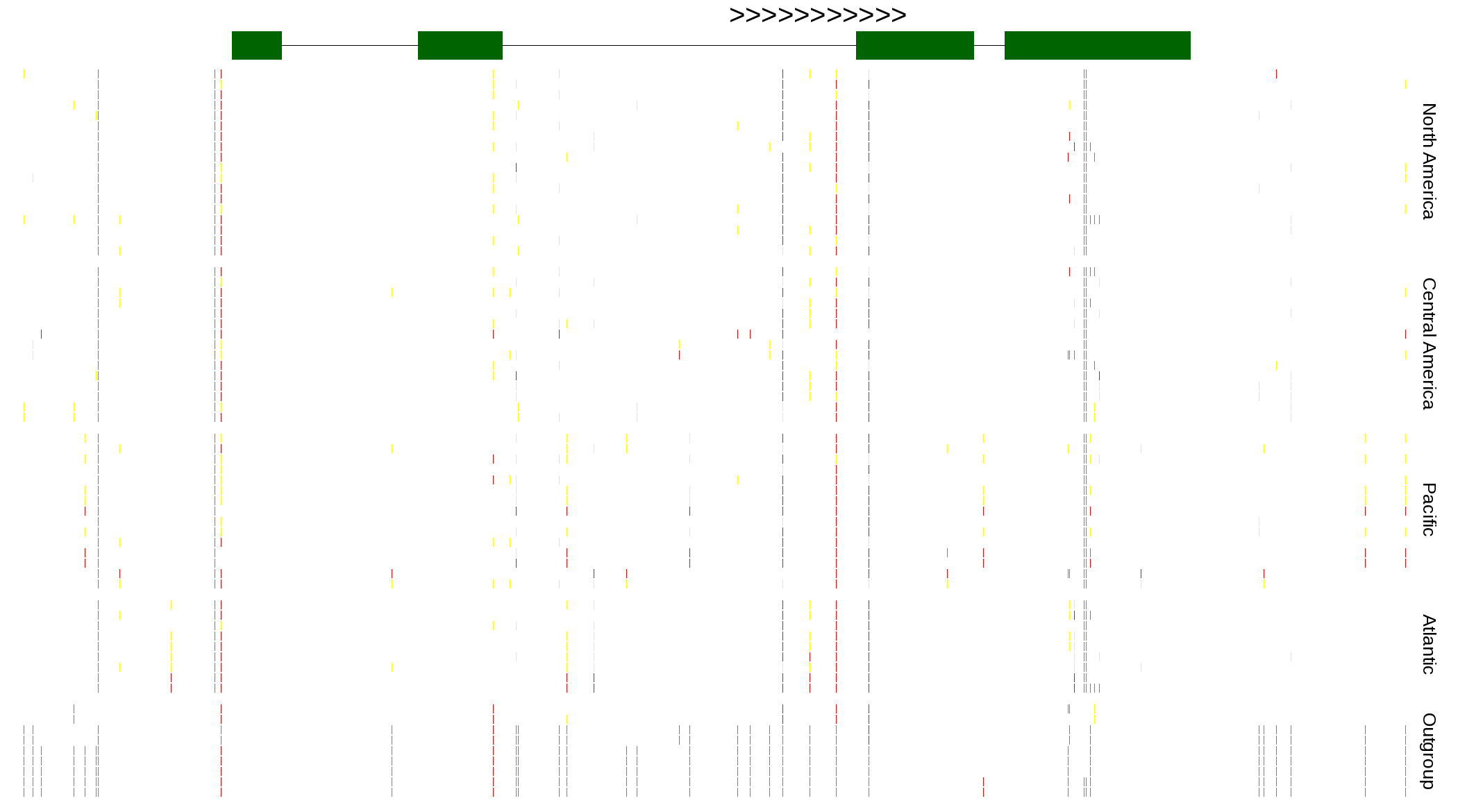
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS210561-TA
ATGGAAAACTTTTCGAGAGTTGAAAAAATTGGTGAAGGAACATATGGCGTAGTTTATAAGGCAAGAGACAAAGTAACCGGTAAAGAAATTGCTCTGAAGAAAATAAAACTTGAAAATGAACCTGAGGGGGTCCCATCAACTGCACTCAGAGAGATATCAGTATTGCGGGAGTTAAAGCACCCGGCTGTGGTGCGCTTACTAGATGTGCTGCTGGCAGACACAAAGCTGTTTCTGGTCTTTGAGTTTTTACACATGGACCTCAAACGGCTTATGGATATAACCAAAGGACCACTGCAGCTGGATCTTGTGAAGAGTTACTTGCGACAGCTGTTAGAGGGAGTTGCCTACTGTCACGCACATCGTGTGTTACATCGCGACCTCAAGCCACAGAATCTTCTGGTGGATGTGGAGGGTCACATAAAGCTGGCCGACTTCGGTCTAGCGCGCGCCTTCGGTATACCCGTGCGCGCTTACACTCACGAGGTGGTGACGCTCTGGTACCGGGCGCCCGAGATCCTGCTAGGAGCCAAGTTCTACTCCACTGCCGTCGACGTCTGGAGTCTCGCCTGCATCTACGCCGAGATGGCCAGCGGCAGGACGCTATTTCCGGGCGACAGCGAGATCGATCAGCTGTTCAGAGTGTTCCGCGCCCTGGGTACGCCCGGCGAGGACGTGTGGCCCGGAGCGCGCCTGCTGCCCGACTACCGCGCCGCCTTTCCTCGCTGGCCGCGCCGCGAGGCCCGCCTGCTTCTGCCGGCGGCGGACTCGGGCTCCGCCGCACGCCCCACACGCCGCGAGCCTGTTCGAGAGCATGTTGCGGTACGAGCCGAGCGAGCGCGTGTCGGCGCGCGCCGCCCTGCTGCACCCTTACCTGTCGAACGCGCGCCTGGTGCCGCCCGCCCTGCCGCCGCAGCATTCTCCGCCTTCCACCGACTGCGCCGATCGTCCCGACGACTTCTGATCTCCGTCGAGTTGATTTCGTTGTCACCTGTAAATAAATATTTATATTTTTTTTAA
>DPOGS210561-PA
MENFSRVEKIGEGTYGVVYKARDKVTGKEIALKKIKLENEPEGVPSTALREISVLRELKHPAVVRLLDVLLADTKLFLVFEFLHMDLKRLMDITKGPLQLDLVKSYLRQLLEGVAYCHAHRVLHRDLKPQNLLVDVEGHIKLADFGLARAFGIPVRAYTHEVVTLWYRAPEILLGAKFYSTAVDVWSLACIYAEMASGRTLFPGDSEIDQLFRVFRALGTPGEDVWPGARLLPDYRAAFPRWPRREARLLLPAADSGSAARPTRREPVREHVAVRAERARVGARRPAAPLPVERAPGAARPAAAAFSAFHRLRRSSRRLLISVELISLSPVNKYLYFF-