| DPOGS212990 | ||
|---|---|---|
| Transcript | DPOGS212990-TA | 843 bp |
| Protein | DPOGS212990-PA | 280 aa |
| Genomic position | DPSCF300024 - 867292-868274 | |
| RNAseq coverage | 187x (Rank: top 49%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL007697 | 8e-124 | 74.72% | |
| Bombyx | BGIBMGA006905-TA | 2e-118 | 77.20% | |
| Drosophila | Fuca-PB | 2e-91 | 56.74% | |
| EBI UniRef50 | UniRef50_D6WGK4 | 2e-101 | 60.00% | Putative uncharacterized protein n=3 Tax=Tribolium castaneum RepID=D6WGK4_TRICA |
| NCBI RefSeq | XP_971511.1 | 4e-102 | 60.00% | PREDICTED: similar to AGAP007285-PA [Tribolium castaneum] |
| NCBI nr blastp | gi|270003719 | 7e-101 | 60.00% | hypothetical protein TcasGA2_TC002989 [Tribolium castaneum] |
| NCBI nr blastx | gi|270003719 | 2e-106 | 62.45% | hypothetical protein TcasGA2_TC002989 [Tribolium castaneum] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0005975 | 5e-157 | carbohydrate metabolic process | |
| GO:0004560 | 5e-157 | alpha-L-fucosidase activity | ||
| GO:0043169 | 1.1e-90 | cation binding | ||
| GO:0003824 | 1.1e-90 | catalytic activity | ||
| GO:0006004 | 1.6e-47 | fucose metabolic process | ||
| KEGG pathway | tca:660163 | 1e-101 | ||
| K01206 (E3.2.1.51, FUCA) | maps-> | Other glycan degradation | ||
| InterPro domain | [1-280] IPR000933 | 5e-157 | Glycoside hydrolase, family 29 | |
| [34-279] IPR013781 | 1.1e-90 | Glycoside hydrolase, subgroup, catalytic core | ||
| [35-279] IPR017853 | 9.3e-80 | Glycoside hydrolase, superfamily | ||
| [90-105] IPR016286 | 1.6e-47 | Glycoside hydrolase, family 29, bacteria/metazoa/fungi | ||
| Orthology group | MCL10808 | Multiple-copy universal gene | ||
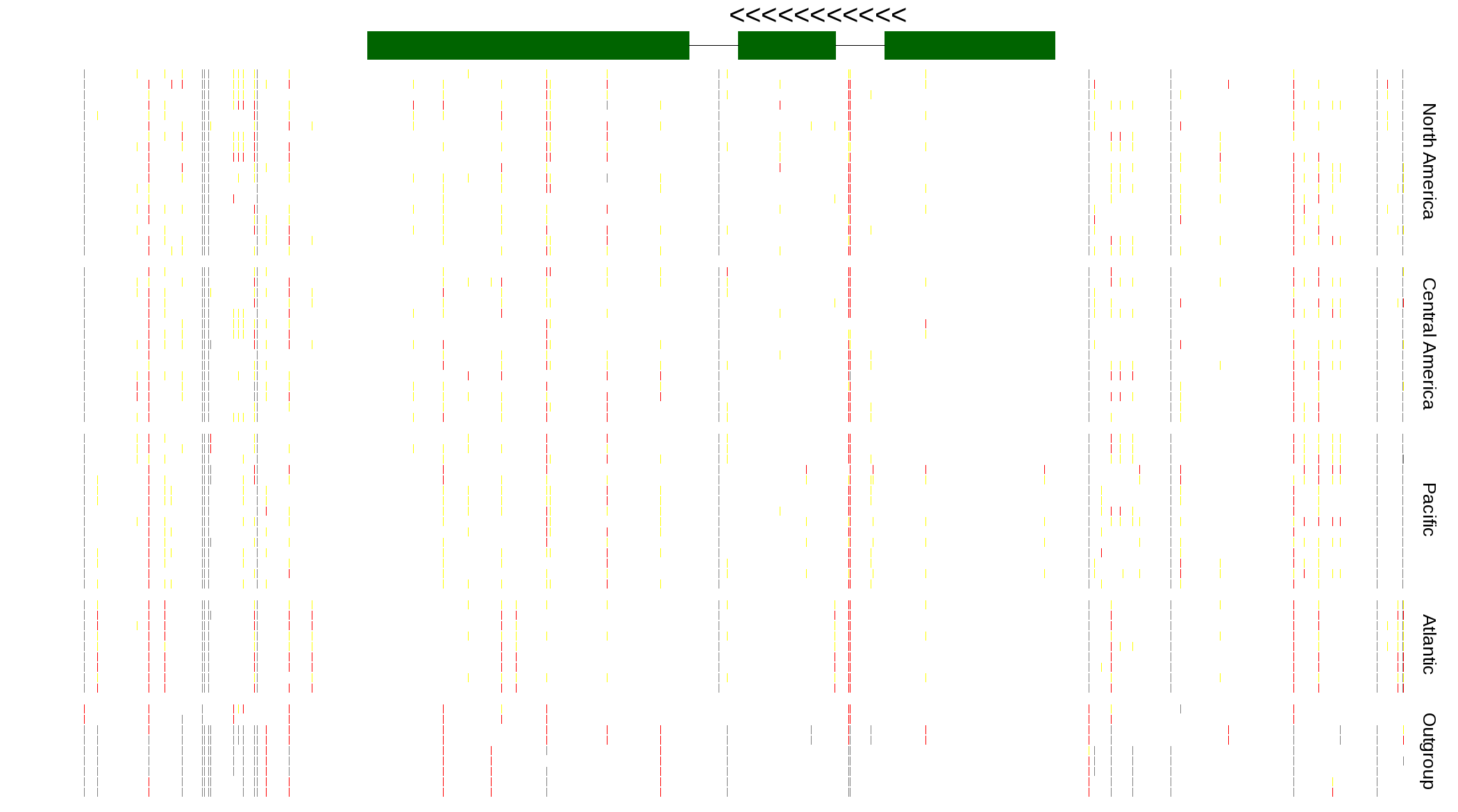
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS212990-TA
ATGAGATGGTTATTGCTGTTACCTGTACTAATCGCTACAACTTCCCCAATAAGTGCTAGTATAAGAAGCTGGGAAGAAGCGGTTCAAGATGTAAAAGGAAAAAAATATTCTCCAAAGTGGCCTAGCCTTGATAGTCGACCTTTGCCAGAATGGTTTGATCGTGCTAAAATCGGCATCTTCCTTCACTGGGGATTGTACTCAGTGCCGGGCTTTGGGTCAGAATGGTTTTGGAGTAATTGGAAAGGTGGAGACAATAAAACAGTCAAGTTCATGGAGGCAAACTATCCACCTGGTTTTTCTTATCAAGAATTTGCGCCAATGTTCAAGGCAGAATTTTTTGATCCTGAAAAATGGGCATCTTTATTCCAGAAAGCGGGAGCTAAATATGTAATACTGACTAGTAAGCATCACGAAGGCTATACTTTATTCCCATCAAAGAGATCATTCAGCTGGAATGCAAAAGAAGTAGGTCCAAAAAGAGATCTAGTCAAAGATGTAGCAAATGCTGTGAGGAATAAGAACATGAAGTTTGGCGTGTACCACTCCCTGTATGAATGGTTCAATCCCATATACATTGAAGACAAAAAGAATTTATTTACAACACGGAATTATGTCAATGACAAGCTGTGGCCGGATTTGAAACAACTTGTACATGATTACCACCCGTCTGTTATATGGTCTGACGGGGACTGGGAGGCGTTTGACGTTTATTGGAACTCCACTGCCTTCCTCGCATGGCTTTACAACGACAGTCCAGTTAAGGATACAGTTGTGGTTAACGATAGATGGGGTATCGGTATTCCATGCCACCATGGAGATTTCTACAACTGCGCTGACAGATAA
>DPOGS212990-PA
MRWLLLLPVLIATTSPISASIRSWEEAVQDVKGKKYSPKWPSLDSRPLPEWFDRAKIGIFLHWGLYSVPGFGSEWFWSNWKGGDNKTVKFMEANYPPGFSYQEFAPMFKAEFFDPEKWASLFQKAGAKYVILTSKHHEGYTLFPSKRSFSWNAKEVGPKRDLVKDVANAVRNKNMKFGVYHSLYEWFNPIYIEDKKNLFTTRNYVNDKLWPDLKQLVHDYHPSVIWSDGDWEAFDVYWNSTAFLAWLYNDSPVKDTVVVNDRWGIGIPCHHGDFYNCADR-