| DPOGS215437 | ||
|---|---|---|
| Transcript | DPOGS215437-TA | 822 bp |
| Protein | DPOGS215437-PA | 273 aa |
| Genomic position | DPSCF300298 - 129982-136424 | |
| RNAseq coverage | 1211x (Rank: top 10%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL016321 | 2e-120 | 78.52% | |
| Bombyx | BGIBMGA005727-TA | 3e-134 | 82.66% | |
| Drosophila | CG5840-PA | 3e-81 | 57.14% | |
| EBI UniRef50 | UniRef50_Q9VEJ3 | 4e-79 | 57.14% | Pyrroline-5-carboxylate reductase n=24 Tax=Endopterygota RepID=Q9VEJ3_DROME |
| NCBI RefSeq | XP_975446.1 | 2e-93 | 62.83% | PREDICTED: similar to pyrroline-5-carboxylate reductase [Tribolium castaneum] |
| NCBI nr blastp | gi|91079134 | 4e-92 | 62.83% | PREDICTED: similar to pyrroline-5-carboxylate reductase [Tribolium castaneum] |
| NCBI nr blastx | gi|91079134 | 2e-88 | 63.30% | PREDICTED: similar to pyrroline-5-carboxylate reductase [Tribolium castaneum] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0006561 | 2.4e-113 | proline biosynthetic process | |
| GO:0055114 | 2.4e-113 | oxidation-reduction process | ||
| GO:0004735 | 2.4e-113 | pyrroline-5-carboxylate reductase activity | ||
| GO:0005488 | 2.3e-43 | binding | ||
| GO:0016616 | 6.4e-35 | oxidoreductase activity, acting on the CH-OH group of donors, NAD or NADP as acceptor | ||
| GO:0016491 | 6.4e-35 | oxidoreductase activity | ||
| KEGG pathway | tca:664343 | 6e-93 | ||
| K00286 (E1.5.1.2, proC) | maps-> | Arginine and proline metabolism | ||
| InterPro domain | [1-263] IPR000304 | 2.4e-113 | Pyrroline-5-carboxylate reductase | |
| [1-160] IPR016040 | 2.3e-43 | NAD(P)-binding domain | ||
| [161-270] IPR008927 | 6.4e-35 | 6-phosphogluconate dehydrogenase, C-terminal-like | ||
| [2-98] IPR004455 | 3.9e-18 | NADP oxidoreductase, coenzyme F420-dependent | ||
| Orthology group | MCL12466 | Single-copy universal gene | ||
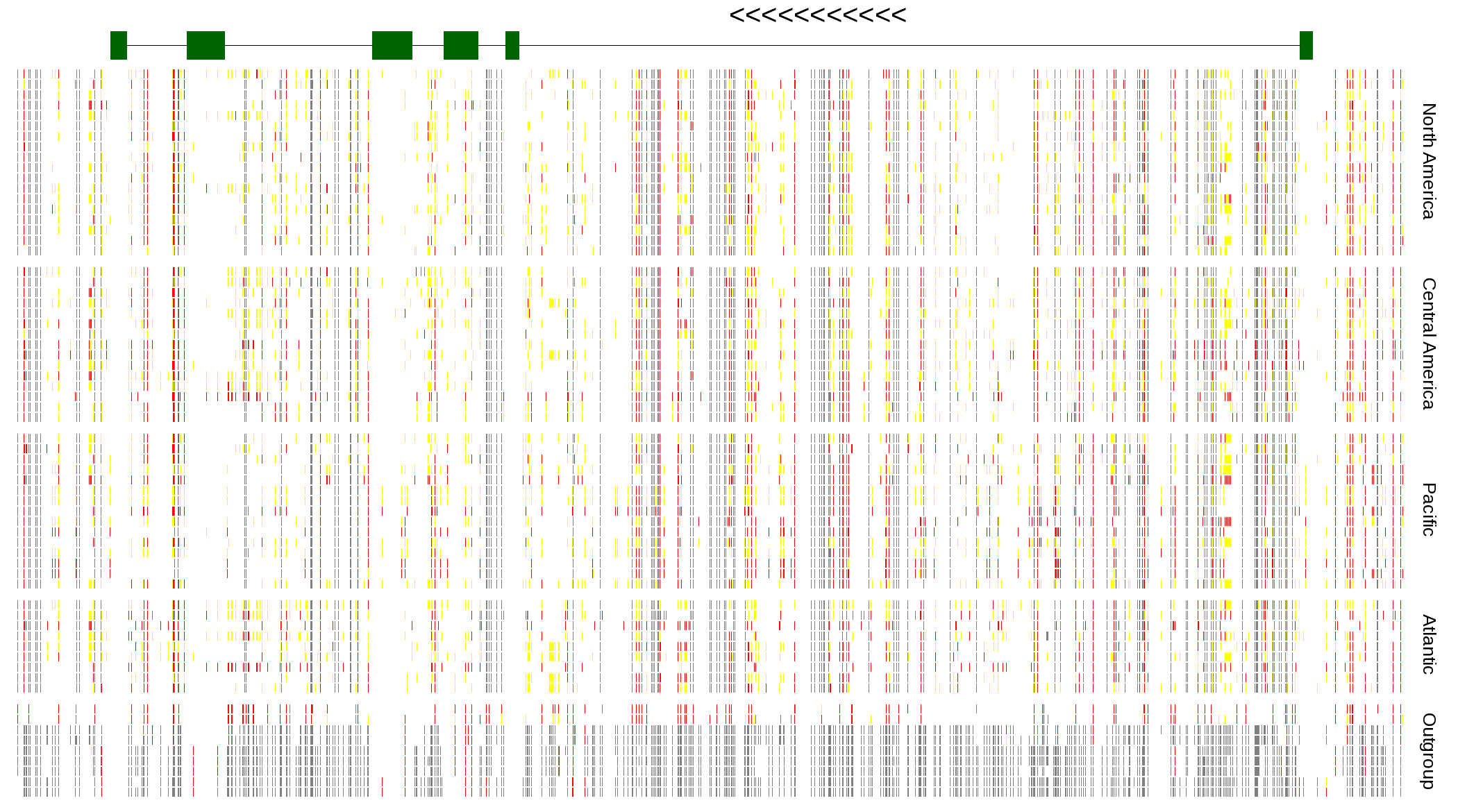
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS215437-TA
ATGAAGATAGGTTTCATCGGAGGCGGTAAACTTGCTTACGCCTTGGCCAATGGCTTTGTTTCTGCAGGATTGGCTAAGCCCGACGAGATTACTGCTAGCTGTCACCCAGCAGATAAGGCTAGCGCCGAAGCATTCAAAAGCTTAGGAGCTACAGCACTATTTGAAAACAAGTCTGTTGTGGAACGCTCAGAAGTAGTTATAGTCTCGGTCAAGCCAGATGTAGTGGTGCCAGCTCTCAAGGATGTCAAAGATCTTGCTGCGTCCAAAAATAAATTATTCATATCAGTGGCCATGGGCGTTTCGACAAGCACCATAGAGAAGGCATTACCGTCAGAAGCACGCGTTATTCGCGTGATGCCGAACACTCCAGCTCTAGTCAAAGAAGGTGCTGCAGCGTTAAGCAGAGGTTCAAAAGCTACAGCAGAGGACGCCAAGTTGGCAGCTGAACTTTTCCGAGCTGTCGGCACGTGTGACGAGGTCCCAGAGTATCAAATGGATGCAGTCACAGCTTTGAGCGGCAGTGGTCCAGCTTATGTGTACATGCTGATAGAGTCCCTAGCGGATGGTGGTGTCCGATGTGGACTCCCCCGGGACCTGGCACTTCGGCTCGCCACCCAGACCACGAGAGGCGCTGCCAGTATGCTGAGTACCGGAAGCCATCCAGCTGTGTTGAAGGACAATGTGACTTCTCCAGCTGGTTCCACAGCCGAGGGGACCTATCACCTGGAACAGAATGGATTCAGATCAGCTGTTATTGGAGCAGTAATGGCTGCGACGAATAGATGTAAGGTCGTTAATGAACAATTAAACCAAATGAATTAA
>DPOGS215437-PA
MKIGFIGGGKLAYALANGFVSAGLAKPDEITASCHPADKASAEAFKSLGATALFENKSVVERSEVVIVSVKPDVVVPALKDVKDLAASKNKLFISVAMGVSTSTIEKALPSEARVIRVMPNTPALVKEGAAALSRGSKATAEDAKLAAELFRAVGTCDEVPEYQMDAVTALSGSGPAYVYMLIESLADGGVRCGLPRDLALRLATQTTRGAASMLSTGSHPAVLKDNVTSPAGSTAEGTYHLEQNGFRSAVIGAVMAATNRCKVVNEQLNQMN-