| DPOGS215460 | ||
|---|---|---|
| Transcript | DPOGS215460-TA | 999 bp |
| Protein | DPOGS215460-PA | 332 aa |
| Genomic position | DPSCF300098 - 492932-493930 | |
| RNAseq coverage | 26255x (Rank: top 0%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL008350 | 3e-172 | 94.17% | |
| Bombyx | BGIBMGA007490-TA | 0.0 | 96.08% | |
| Drosophila | Gapdh2-PA | 7e-165 | 84.04% | |
| EBI UniRef50 | UniRef50_P07487 | 9e-163 | 84.04% | Glyceraldehyde-3-phosphate dehydrogenase 2 n=2346 Tax=root RepID=G3P2_DROME |
| NCBI RefSeq | NP_001037386.1 | 0.0 | 95.78% | glyceraldehyde-3-phosphate dehydrogenase [Bombyx mori] |
| NCBI nr blastp | gi|109119903 | 0.0 | 96.08% | glyceraldehyde-3-phosphate dehydrogenase [Bombyx mori] |
| NCBI nr blastx | gi|109119903 | 1e-179 | 96.08% | glyceraldehyde-3-phosphate dehydrogenase [Bombyx mori] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0016620 | 3.4e-283 | oxidoreductase activity, acting on the aldehyde or oxo group of donors, NAD or NADP as acceptor | |
| GO:0055114 | 3.4e-283 | oxidation-reduction process | ||
| GO:0006006 | 1.4e-131 | glucose metabolic process | ||
| GO:0051287 | 1.4e-131 | NAD binding | ||
| GO:0008943 | 1.4e-131 | glyceraldehyde-3-phosphate dehydrogenase activity | ||
| GO:0005488 | 2.4e-78 | binding | ||
| KEGG pathway | nvi:100118170 | 1e-173 | ||
| K00134 (GAPDH, gapA) | maps-> | Glycolysis / Gluconeogenesis | ||
| Alzheimer's disease | ||||
| InterPro domain | [1-332] IPR020831 | 3.4e-283 | Glyceraldehyde/Erythrose phosphate dehydrogenase family | |
| [3-323] IPR006424 | 1.4e-131 | Glyceraldehyde-3-phosphate dehydrogenase, type I | ||
| [2-149] IPR020828 | 1.1e-93 | Glyceraldehyde 3-phosphate dehydrogenase, NAD(P) binding domain | ||
| [2-157] IPR016040 | 2.4e-78 | NAD(P)-binding domain | ||
| [154-311] IPR020829 | 1.2e-71 | Glyceraldehyde 3-phosphate dehydrogenase, catalytic domain | ||
| Orthology group | MCL10097 | Multiple-copy universal gene | ||
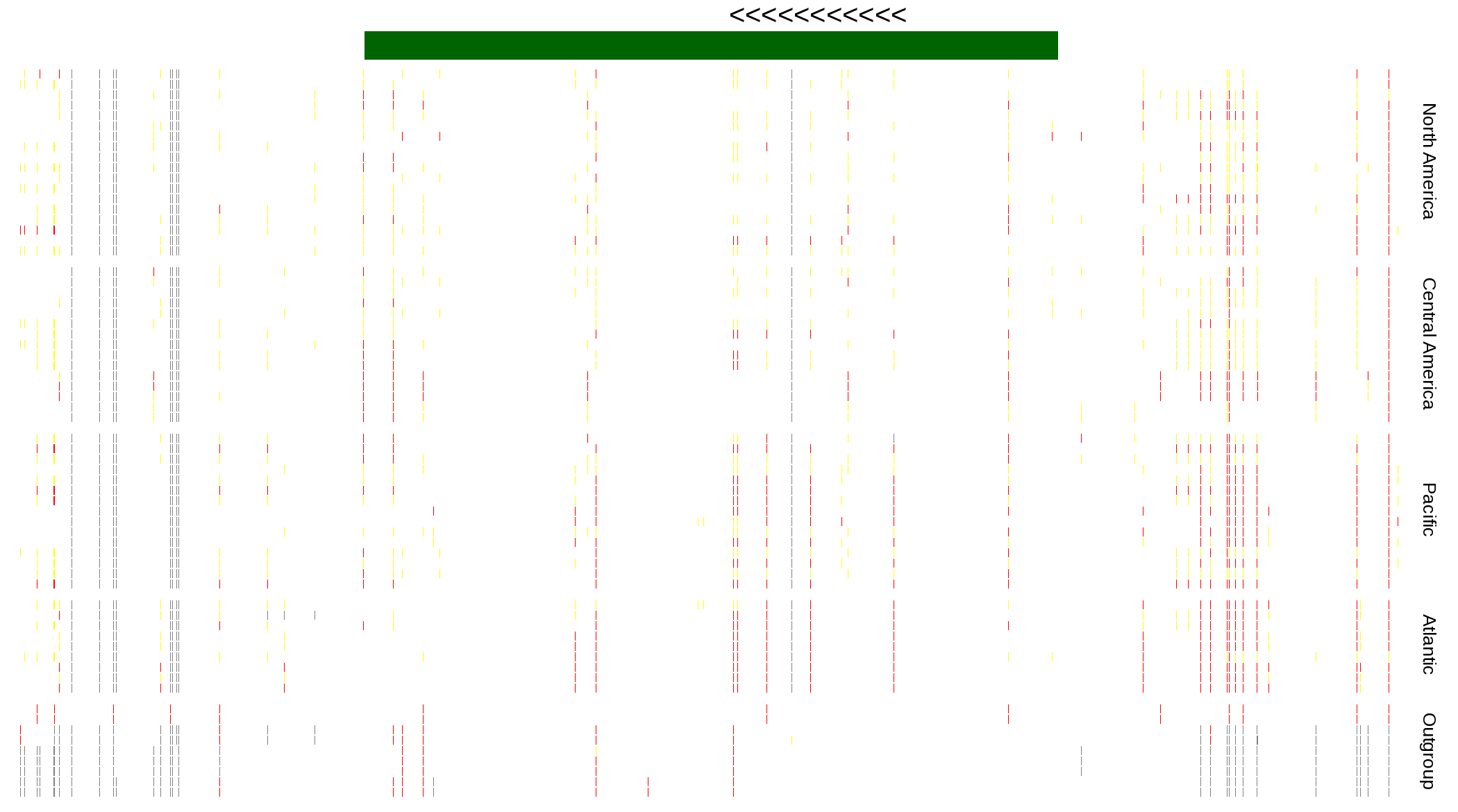
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS215460-TA
ATGTCGAAAATTGGTATCAACGGTTTTGGCCGCATTGGTCGTCTGGTTCTCCGTGCTTCCATTGAAAAGGGGGCTCAAGTTGTAGCAGTCAATGACCCCTTCATTGGCCTAGACTATATGGTCTACATGTTCAAGTATGACTCCACCCATGGACGTTTCAAGGGATCAGTAGAAGCTGTTGACGGCTGTCTAGTTGTTAATGGAAACAAAATTGCTGTTTTCTCTGAGAGGGACCCCAAAGCCATTCCATGGGCCAAGGCCGGTGCTGAATATGTTGTGGAATCAACCGGTGTATTCACCACAACTGATAAGGCATCTGCTCACTTGGAAGGTGGAGCCAAGAAGGTCATCATCTCAGCTCCCAGTGCAGACGCCCCAATGTTCGTAGTGGGTGTCAACCTTGACGCCTACAACCCATCCTACAAGGTCATTTCTAACGCCTCATGCACGACCAACTGTCTGGCTCCGCTTGCCAAAGTTATCCACGACAACTTTGAAATCGTTGAGGGCTTGATGACAACCGTTCACGCCACAACCGCCACTCAGAAGACTGTAGACGGTCCTTCCGGCAAGTTGTGGCGTGACGGCCGTGGTGCCCAGCAGAATATCATCCCAGCTGCCACTGGCGCAGCCAAAGCTGTTGGCAAGGTTATACCGGCTCTGAATGGAAAGTTGACCGGTATGGCGTTCCGCGTGCCCGTAGCTAATGTATCCGTCGTCGATTTGACAGTCCGCCTCGCTAAACCCGCAAGCTACGACGCCATTAAACAGAAGGTCAAGGAAGCGGCCGAGGGACCTCTGAAAGGAATCCTTGGGTACACAGAAGACCAGGTCGTATCTAGTGACTTCATCGGCGACTCCCACTCGTCGATCTTCGACGCCGCAGCGGGTATATCTCTGAACGACAACTTCGTCAAGCTGATCAGCTGGTATGACAACGAGTACGGCTACTCCAGCCGGGTCATCGACCTGATCAAGCACATCCAGAGCAAGGATTAA
>DPOGS215460-PA
MSKIGINGFGRIGRLVLRASIEKGAQVVAVNDPFIGLDYMVYMFKYDSTHGRFKGSVEAVDGCLVVNGNKIAVFSERDPKAIPWAKAGAEYVVESTGVFTTTDKASAHLEGGAKKVIISAPSADAPMFVVGVNLDAYNPSYKVISNASCTTNCLAPLAKVIHDNFEIVEGLMTTVHATTATQKTVDGPSGKLWRDGRGAQQNIIPAATGAAKAVGKVIPALNGKLTGMAFRVPVANVSVVDLTVRLAKPASYDAIKQKVKEAAEGPLKGILGYTEDQVVSSDFIGDSHSSIFDAAAGISLNDNFVKLISWYDNEYGYSSRVIDLIKHIQSKD-