| DPOGS200425 | ||
|---|---|---|
| Transcript | DPOGS200425-TA | 687 bp |
| Protein | DPOGS200425-PA | 228 aa |
| Genomic position | DPSCF300236 - 86963-88221 | |
| RNAseq coverage | 263x (Rank: top 40%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL000022 | 1e-24 | 32.21% | |
| Bombyx | BGIBMGA008998-TA | 6e-35 | 52.48% | |
| Drosophila | CG6984-PA | 3e-68 | 51.75% | |
| EBI UniRef50 | UniRef50_B0WFW8 | 4e-75 | 55.70% | Cyclohex-1-ene-1-carboxyl-CoA hydratase n=6 Tax=Endopterygota RepID=B0WFW8_CULQU |
| NCBI RefSeq | XP_001661868.1 | 2e-80 | 59.65% | cyclohex-1-ene-1-carboxyl-CoA hydratase, putative [Aedes aegypti] |
| NCBI nr blastp | gi|157130280 | 3e-79 | 59.65% | cyclohex-1-ene-1-carboxyl-CoA hydratase, putative [Aedes aegypti] |
| NCBI nr blastx | gi|157130280 | 1e-74 | 59.65% | cyclohex-1-ene-1-carboxyl-CoA hydratase, putative [Aedes aegypti] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0008152 | 4.8e-37 | metabolic process | |
| GO:0003824 | 4.8e-37 | catalytic activity | ||
| KEGG pathway | cpb:Cphamn1_2111 | 4e-57 | ||
| K01692 (E4.2.1.17, paaG) | maps-> | Benzoate degradation via CoA ligation | ||
| Propanoate metabolism | ||||
| Limonene and pinene degradation | ||||
| Tryptophan metabolism | ||||
| Lysine degradation | ||||
| Valine, leucine and isoleucine degradation | ||||
| beta-Alanine metabolism | ||||
| Geraniol degradation | ||||
| Fatty acid metabolism | ||||
| Caprolactam degradation | ||||
| Butanoate metabolism | ||||
| InterPro domain | [1-152] IPR001753 | 4.8e-37 | Crotonase, core | |
| Orthology group | MCL15107 | Single-copy universal gene | ||
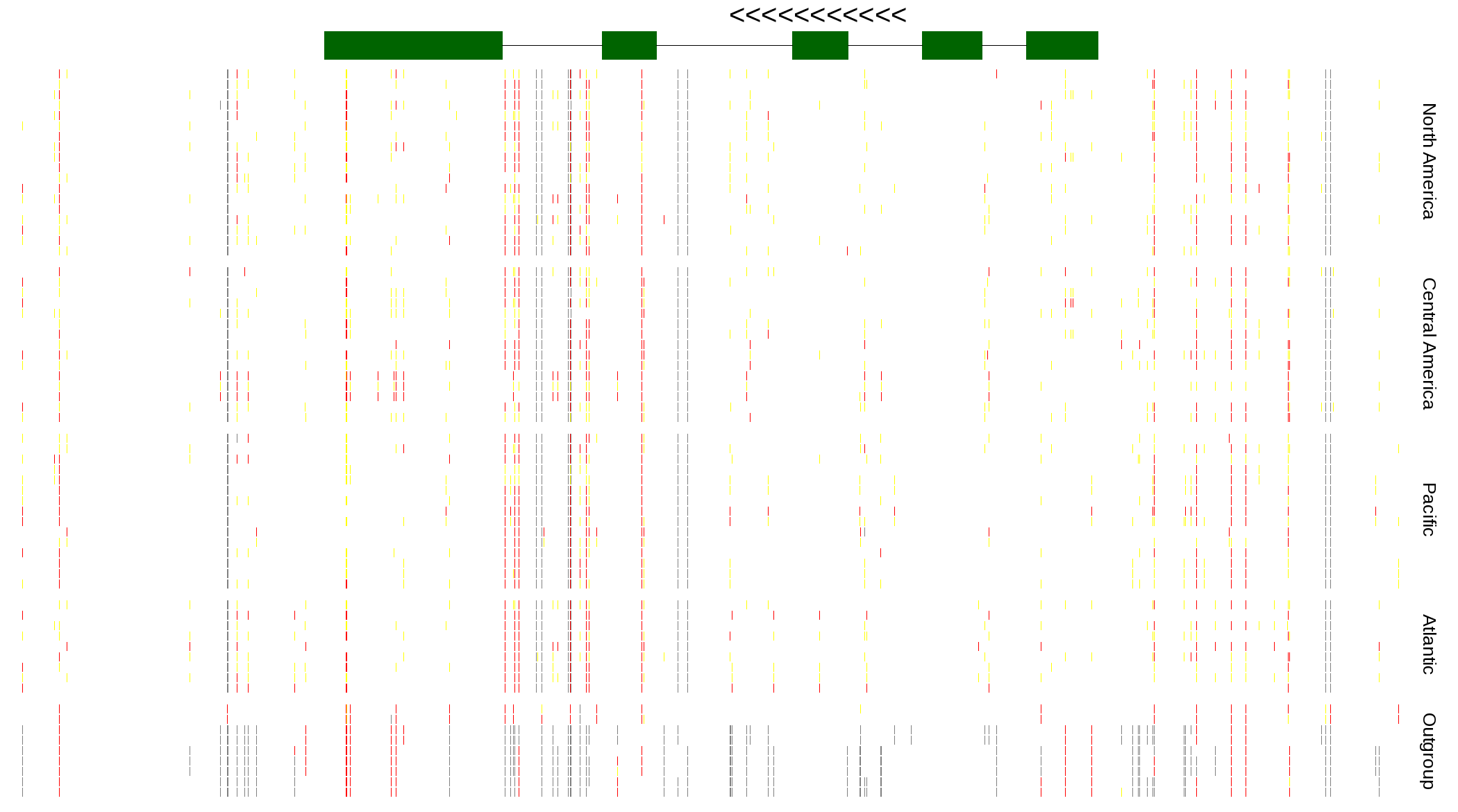
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS200425-TA
ATGATGAACAGCCTTATAGAAGCATTAAATCTCAATAAAGGAGATACCTCATTGCGAGCTATTGTTTTATCTGCAAAGGGTAATGTTTTTTCCGCTGGTCATAATTTAAAGGAATTACAAATTTCATCGGATTTAGAGAAACAAAAATTAATATTTCAAAAAGCCACTGAATTGATGACTTCCATTATTCAAAGTCCAGTTCCAGTTATAGCAAAGGTTAATGGATTTGCAGCAGCGGCTGGGTGTCAGTTAGTGGCTACTTGCGACATTATAATTTGCTCTGACAAAAGCAAATTTTCAACCCCAGGTGCTAACTTTGGTATATTCTGTTCAACACCAGGAATTGCTATCGGCAGAAGTGTCCCTAAGTCGAGGGCTATGTATATGTTGTTAACTGGTGAGCCCTTAAGTGCCCAAGAAGCCTATGAAAGTGGACTCGTCACAAAAGTTGTACCTGCTGAAAAGCTTGATTCTGAAGTTAATGAAACTATTGAACAGATTAAACGTAAAAGTAGAAGTGTAATATCACTTGGAAAAGAGTTTTTCTACAAACAGATCGGTCTCAATGTTCTAGATGCGTACAGACTGGGTGAAGAAATCATGGTCAAGAATATAAACTCACTTGACGGACAAGAGGGAATAAACAGTTTCATAGAAAAACGTAAAGCTGTATGGAATCACAAGTAG
>DPOGS200425-PA
MMNSLIEALNLNKGDTSLRAIVLSAKGNVFSAGHNLKELQISSDLEKQKLIFQKATELMTSIIQSPVPVIAKVNGFAAAAGCQLVATCDIIICSDKSKFSTPGANFGIFCSTPGIAIGRSVPKSRAMYMLLTGEPLSAQEAYESGLVTKVVPAEKLDSEVNETIEQIKRKSRSVISLGKEFFYKQIGLNVLDAYRLGEEIMVKNINSLDGQEGINSFIEKRKAVWNHK-