| DPOGS203911 | ||
|---|---|---|
| Transcript | DPOGS203911-TA | 699 bp |
| Protein | DPOGS203911-PA | 232 aa |
| Genomic position | DPSCF300005 - 882755-884957 | |
| RNAseq coverage | 24x (Rank: top 77%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL003974 | 4e-97 | 80.00% | |
| Bombyx | BGIBMGA002432-TA | 1e-60 | 52.42% | |
| Drosophila | Vha100-2-PB | 1e-57 | 49.78% | |
| EBI UniRef50 | UniRef50_Q9VE75 | 1e-55 | 49.78% | Vha100-2, isoform A n=19 Tax=Coelomata RepID=Q9VE75_DROME |
| NCBI RefSeq | XP_396263.3 | 2e-57 | 53.57% | PREDICTED: similar to Vha100-2 CG18617-PB, isoform B isoform 1 [Apis mellifera] |
| NCBI nr blastp | gi|328785772 | 7e-56 | 53.57% | PREDICTED: v-type proton ATPase 116 kDa subunit a isoform 1-like isoform 1 [Apis mellifera] |
| NCBI nr blastx | gi|270002624 | 6e-55 | 50.22% | hypothetical protein TcasGA2_TC004949 [Tribolium castaneum] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0015991 | 1e-98 | ATP hydrolysis coupled proton transport | |
| GO:0033177 | 1e-98 | proton-transporting two-sector ATPase complex, proton-transporting domain | ||
| GO:0015078 | 1e-98 | hydrogen ion transmembrane transporter activity | ||
| KEGG pathway | ame:412810 | 6e-57 | ||
| K02154 (ATPeVI, ATP6N1A) | maps-> | Collecting duct acid secretion | ||
| Oxidative phosphorylation | ||||
| Lysosome | ||||
| Phagosome | ||||
| Vibrio cholerae infection | ||||
| Epithelial cell signaling in Helicobacter pylori infection | ||||
| InterPro domain | [1-221] IPR002490 | 1e-98 | ATPase, V0/A0 complex, 116kDa subunit | |
| Orthology group | MCL34523 | Lepidoptera specific | ||
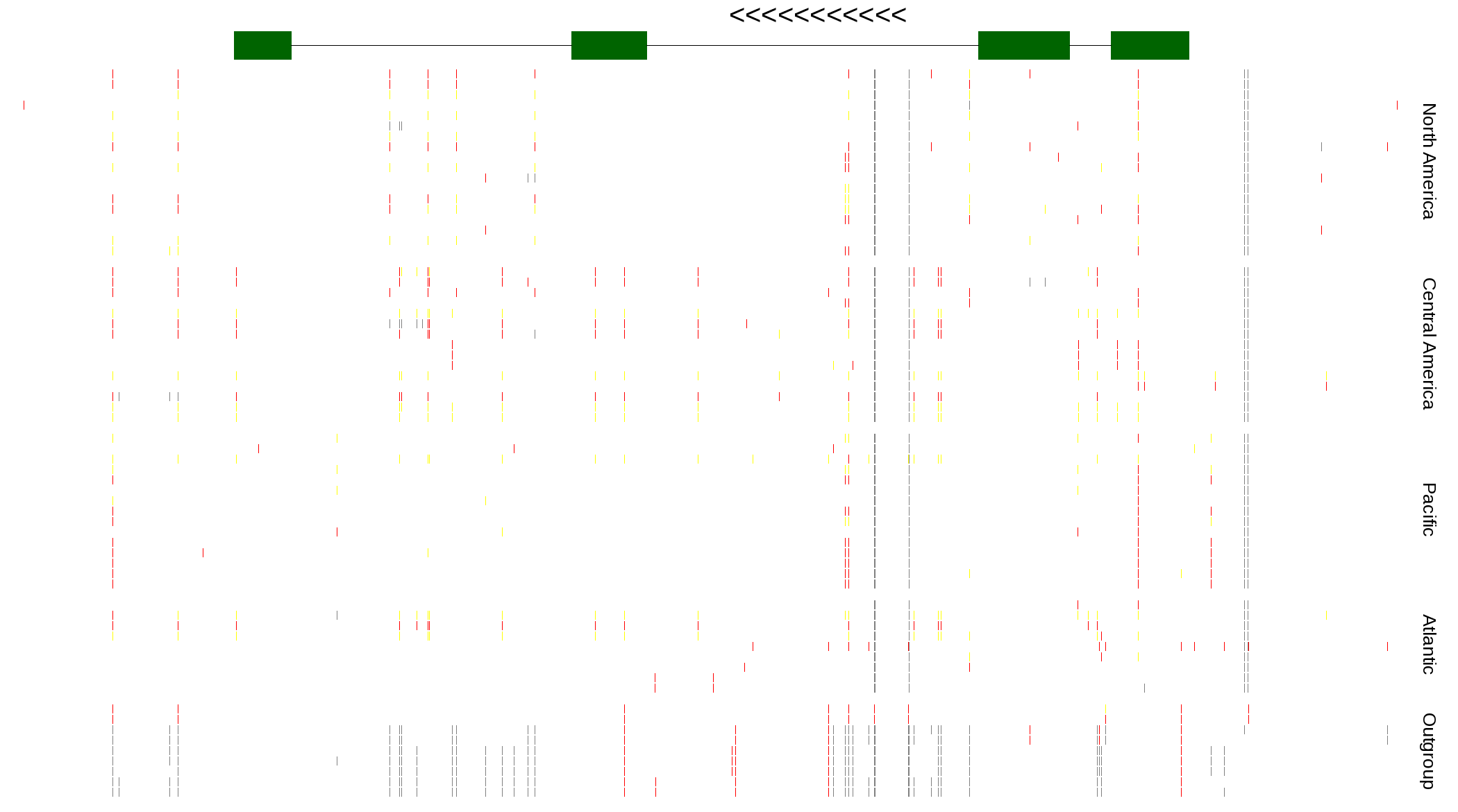
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS203911-TA
ATGGTTCTTTTATCAACGTCAAAACCGGTTGAAGAAGACTGTGATGCTTACATGTTCAGTAACCAGGAACGTTTTCAACGATTATTGGTCATAATTGGAGTAATTTGTGTTCCAATTCTATTATTTGGAACACCGGTATATCTCAATAAGGCCAATAAGAAAAAGAAAGCTGAAGCCCTTAAAAAGGTTAGTCAATTTCGAAGGTATCAGCGGCGTGAATCCGATAACAAGCGAGTGGAAGATAAAATACTAAAAGAAGTAGCAAAGTACTCAGTACCTTTTGGCGAACTAATGATTCATCAAGCTGTGCACACGATCGAATTTGTACTAAGCACTATATCCCACACGGCCTCCTACCTACGTCTGTGGGCGCTGTCCTTAGCACATGAACAATTGTCGGAGATGTTATGGGTAATGGTGTTTGCTAAGCTTGGTTTACGAGAATATTCAATGACTGGCGGTGTTAAAATATTTCTCATATTTGCTGTTTGGGCGGTCTTCAGTCTTTCAATCTTAGTAGTTATGGAAGGATTGTCCGCGTTCCTTCATACTTTACGATTGCATTGGGTTGAATTTATGAGCAAGTTCTATTCTGGAACAGGCTATCCGTTTAAACCCTTTAGTTTTAAAGCAATTTTAAGCGGCGAAGGCAAAGATGACAAATCTGAGGCAATGTGTAAGAAGAAGGTCGCAAATTAA
>DPOGS203911-PA
MVLLSTSKPVEEDCDAYMFSNQERFQRLLVIIGVICVPILLFGTPVYLNKANKKKKAEALKKVSQFRRYQRRESDNKRVEDKILKEVAKYSVPFGELMIHQAVHTIEFVLSTISHTASYLRLWALSLAHEQLSEMLWVMVFAKLGLREYSMTGGVKIFLIFAVWAVFSLSILVVMEGLSAFLHTLRLHWVEFMSKFYSGTGYPFKPFSFKAILSGEGKDDKSEAMCKKKVAN-