| DPOGS204843 | ||
|---|---|---|
| Transcript | DPOGS204843-TA | 957 bp |
| Protein | DPOGS204843-PA | 318 aa |
| Genomic position | DPSCF300227 - 158539-164789 | |
| RNAseq coverage | 12196x (Rank: top 1%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL013893 | 7e-104 | 63.25% | |
| Bombyx | % | |||
| Drosophila | crc-PA | 4e-16 | 31.44% | |
| EBI UniRef50 | UniRef50_Q9GPH3 | 6e-59 | 68.27% | Activating transcription factor of chaperone n=1 Tax=Bombyx mori RepID=ATFC_BOMMO |
| NCBI RefSeq | NP_001037041.1 | 1e-59 | 68.27% | activating transcription factor of chaperone [Bombyx mori] |
| NCBI nr blastp | gi|112983140 | 2e-58 | 68.27% | activating transcription factor of chaperone [Bombyx mori] |
| NCBI nr blastx | gi|112983140 | 3e-66 | 69.38% | activating transcription factor of chaperone [Bombyx mori] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0006355 | 1.7e-11 | regulation of transcription, DNA-dependent | |
| GO:0043565 | 1.7e-11 | sequence-specific DNA binding | ||
| GO:0003700 | 1.7e-11 | sequence-specific DNA binding transcription factor activity | ||
| GO:0046983 | 9.6e-08 | protein dimerization activity | ||
| KEGG pathway | ame:410226 | 4e-33 | ||
| K04374 (ATF4, CREB2) | maps-> | GnRH signaling pathway | ||
| Prostate cancer | ||||
| MAPK signaling pathway | ||||
| Neurotrophin signaling pathway | ||||
| Long-term potentiation | ||||
| Protein processing in endoplasmic reticulum | ||||
| InterPro domain | [245-309] IPR004827 | 1.7e-11 | Basic-leucine zipper (bZIP) transcription factor | |
| [247-304] IPR011616 | 9.6e-08 | bZIP transcription factor, bZIP-1 | ||
| Orthology group | MCL17726 | Insect specific | ||
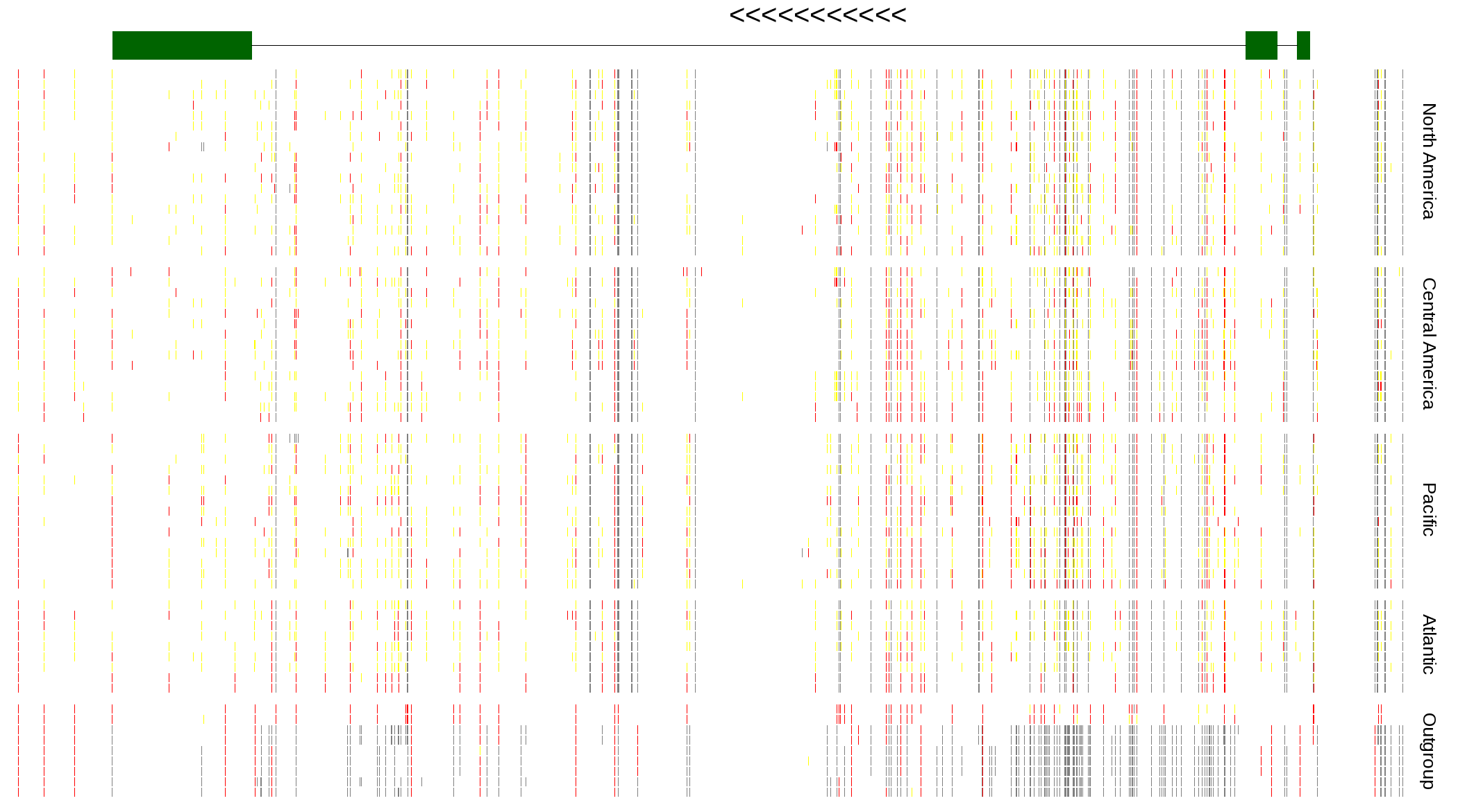
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS204843-TA
ATGTGCTGTTACAAGAATAAAGGAATGTGCGATCTGTGTAGAGATTTTCAGCTATCGTTGTTTCAAAATATTCTTAAGAGCTTTCCGGGCGCTGCAACAAAGATCGAAACGGCTAGCTTCCAAGATGACCTTACCAACACCATGTACCCACCATCTCCTGTGGACATCAAGCCCAGTCAAGCGGAGCGAGCTGAAGATCTGCTGCAGCAGCTGGAAAGTCAATGCAAACAAGAAAACATATACTCTAACTGGTTCGAAGAGAAAGTTGAGAACAGCATCTTCGATAATATCAGTCAGGGACCAGAGCCGGAGTTCCGGCCGGTGGCTGTCGATTACACCGCGCAGACCGTGCCGCGCTCCACCGAGGTTCTTTTGAGGGAGTTCGAGTCGGTGTACAGTGGCGTCCAACTGACTCACCTCACCCCGCCTCAGAGCCCGCCCGGTCCGGCTACCCAACTCCTGCTAAGCTACGCCCAAGCTCAGGCTGCTCCGCCTTTACAACCACTAACTGTCGAGCAATGGCCATTGATCCCGCCCCAAAGCTCAATACCGGAGTACGACTGCGATCCTCAGGCCCTCGAGGAGTTGGTCCGCCATCGTGCCGCTCAATTGGAATCGCCGCAGCCCGCGCACAGCCCTTCACCATCACCGCAATCATCACCGTCCTCATCGCCGCGGTCATCTTCCACTGATGAGGATTGGACATCATCCCGCCCCAAGCCGTACTCCCGGAACGGTGATGATCGCAGGTCTCGTAAGAAGGAGCAGAACAAGAATGCGGCTACCCGTTACCGCCAGAAGAAGAAAGCCGAGATCGAGGTGCTCCTCAACGAGGAACAGGAGCTGCGCAAGCGACACGGTGAGCTCGGGGACAAGTGTTCCGACCTCCAACGCGAGATCCGCTACATCAAGGGCATCCTGCGCGACCTCTTCAAGGCAAAAGGCCTCATCAAATAG
>DPOGS204843-PA
MCCYKNKGMCDLCRDFQLSLFQNILKSFPGAATKIETASFQDDLTNTMYPPSPVDIKPSQAERAEDLLQQLESQCKQENIYSNWFEEKVENSIFDNISQGPEPEFRPVAVDYTAQTVPRSTEVLLREFESVYSGVQLTHLTPPQSPPGPATQLLLSYAQAQAAPPLQPLTVEQWPLIPPQSSIPEYDCDPQALEELVRHRAAQLESPQPAHSPSPSPQSSPSSSPRSSSTDEDWTSSRPKPYSRNGDDRRSRKKEQNKNAATRYRQKKKAEIEVLLNEEQELRKRHGELGDKCSDLQREIRYIKGILRDLFKAKGLIK-