| DPOGS206880 | ||
|---|---|---|
| Transcript | DPOGS206880-TA | 2784 bp |
| Protein | DPOGS206880-PA | 927 aa |
| Genomic position | DPSCF300001 - 2087847-2095504 | |
| RNAseq coverage | 286x (Rank: top 38%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL010497 | 0.0 | 85.11% | |
| Bombyx | BGIBMGA014201-TA | 0.0 | 82.94% | |
| Drosophila | CG8665-PA | 0.0 | 62.02% | |
| EBI UniRef50 | UniRef50_B0WX46 | 0.0 | 64.78% | 10-formyltetrahydrofolate dehydrogenase n=15 Tax=Coelomata RepID=B0WX46_CULQU |
| NCBI RefSeq | XP_969916.1 | 0.0 | 68.06% | PREDICTED: similar to aldehyde dehydrogenase [Tribolium castaneum] |
| NCBI nr blastp | gi|383859222 | 0.0 | 68.60% | PREDICTED: cytosolic 10-formyltetrahydrofolate dehydrogenase-like [Megachile rotundata] |
| NCBI nr blastx | gi|383859222 | 0.0 | 68.60% | PREDICTED: cytosolic 10-formyltetrahydrofolate dehydrogenase-like [Megachile rotundata] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0008152 | 6.5e-177 | metabolic process | |
| GO:0055114 | 6.5e-177 | oxidation-reduction process | ||
| GO:0016491 | 6.5e-177 | oxidoreductase activity | ||
| GO:0016620 | 5.8e-69 | oxidoreductase activity, acting on the aldehyde or oxo group of donors, NAD or NADP as acceptor | ||
| GO:0009058 | 3.4e-51 | biosynthetic process | ||
| GO:0016742 | 3.4e-51 | hydroxymethyl-, formyl- and related transferase activity | ||
| GO:0003824 | 1.5e-14 | catalytic activity | ||
| GO:0000036 | 6e-07 | acyl carrier activity | ||
| GO:0048037 | 5.2e-06 | cofactor binding | ||
| KEGG pathway | xtr:496436 | 0.0 | ||
| K00289 (E1.5.1.6, FTHFD) | maps-> | One carbon pool by folate | ||
| InterPro domain | [455-922] IPR015590 | 6.5e-177 | Aldehyde dehydrogenase domain | |
| [429-927] IPR016161 | 4.4e-174 | Aldehyde/histidinol dehydrogenase | ||
| [446-711] IPR016162 | 2.1e-105 | Aldehyde dehydrogenase, N-terminal | ||
| [712-898] IPR016163 | 5.8e-69 | Aldehyde dehydrogenase, C-terminal | ||
| [15-217] IPR002376 | 3.4e-51 | Formyl transferase, N-terminal | ||
| [219-334] IPR011034 | 1.5e-14 | Formyl transferase, C-terminal-like | ||
| [222-333] IPR005793 | 4.3e-11 | Formyl transferase, C-terminal | ||
| [344-415] IPR009081 | 6e-07 | Acyl carrier protein-like | ||
| [356-413] IPR006163 | 5.2e-06 | Phosphopantetheine-binding | ||
| Orthology group | MCL12052 | Multiple-copy universal gene | ||
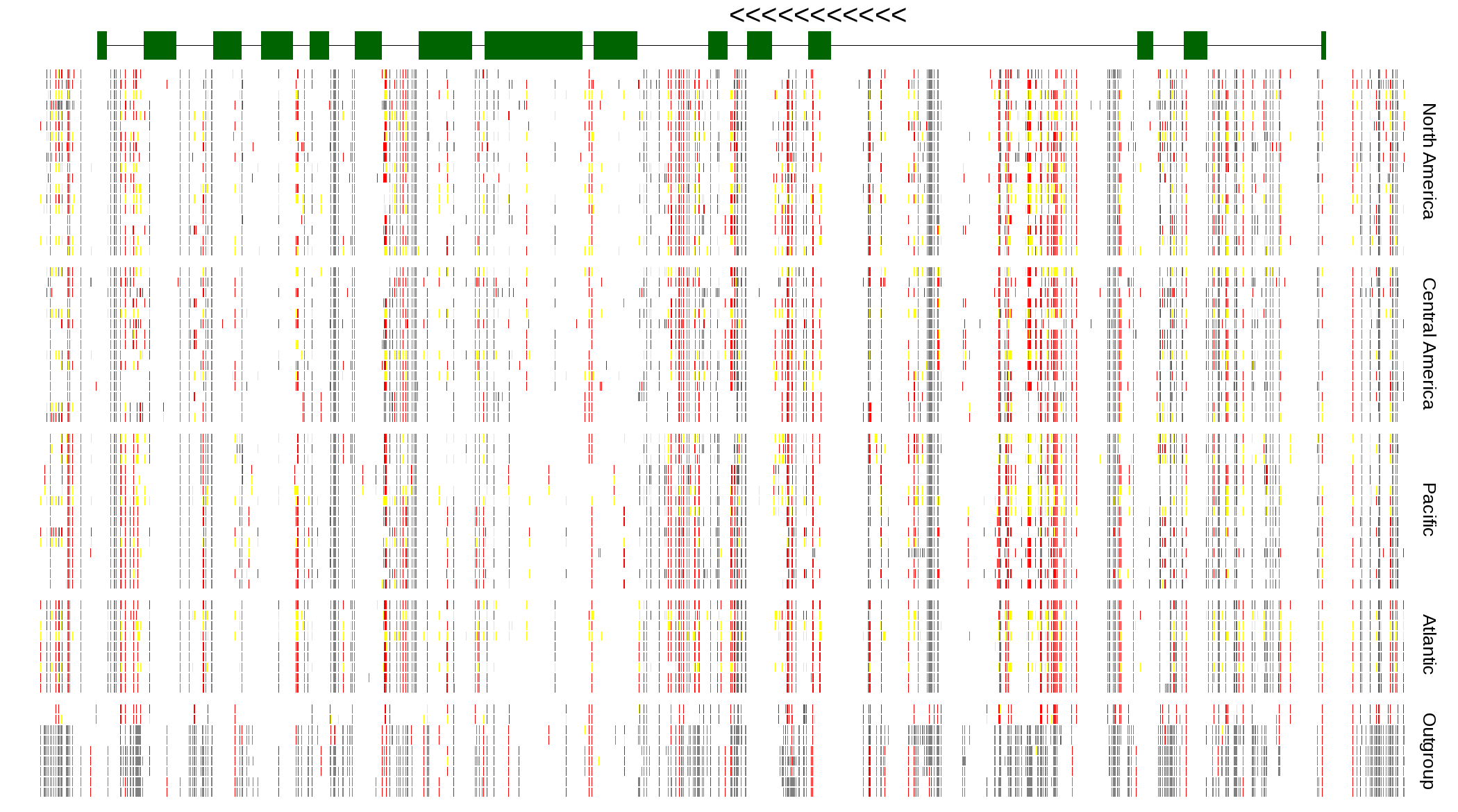
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS206880-TA
ATGCCACCAGTAGCTGTGCCCGAGGAGCCTTCCAAGAAAAAGCTCCGTGTAGCCATAATAGGTCAGAGTACTTTCGCTGCTGAGGTGTTCAAATTACTACAGAGAGATGGTCATGAAGTGGTCGGTGTATTCACAGTACTCGATAAAGGAAATCGAGAAGACCCGTTGGCCACGATCGCAGCCCAGAACGGTAAACCAGTGTTCAAATACAAGACGTGGAGGGTGAAAGGACAAGTTATACCGGGAATATTAGAGGAGTACAAATCTGTAAACGCCGACATCAACGTTCTACCGTTCTGTACTCAATTTATTCCCATGGAAGTTATTCTGCATCCGAAATATCAGAGTATCTGCTACCATCCCAGCATCTTACCTAGGCATAGAGGAGCGTCGTCTATCAATTGGACCCTTATCGAAGGTGACACCACCTGCGGTCTCACTATCTTCTGGGCAGATGACGGCTTGGACACTGGGCCCATTTTACTACAGAGAAGTTTTCCTTGCACTATTGATGACACTGTTGACTCACTGTACAATAAATATTTATATCCTGAGGGCATCAAAGCATTGGCAGAATCTGTGAATATGGTGGCTAATGGAGTAGCTCCGCGGATAAAACAAACCGAAGAGGGAGCTACATACGATCCAGCACTCTTTAAACCAGAAACACATCAGATTGATTGGTCTAAAGGTGGTCTCGCTTTACACAATTTTATACGTGGTCTGGATTCATCCCCTGGCGCTACCACCTTCATAAAACCACAAAACAAAGACGGCGTTGATAAAACCAGTGATGCCAACATTGAAATTAAGTTCTTTGGTTCCTCATTGTGGGAAGCGGAGTACGAAACAGAGGGTGATAAATTATTTATCACAGGATTAAACAAACCAGCCGTGGTACACGCTGATGGTTTATTAATAACAGCTAATGATGGAATTAAGCTTAACATTCAGAGGTTGAAAGTAAACGGTAAGATGATTAATGCCCAAAACTTTTATAAAGGCAGTGAGAACAAAGTCTCCCTTGATTTAACTGCGGAAGAGAAACAGTTCATAGAAAAAGCACGTGATGTTTGGAAAGCAATATTAAGAATCGAAATAGAAAACGATACTGACTTCTTCGCTTCTGGAGCAGGCTCCATGGACGTTGTCAGATTAGTAGAAGAAATAAAGGATATATCAGAACTCGAATTACAAAATGAAGATATTTACATGAACACAACATTTGAAGATTTTTATAATGCAGCTATACTTAAACAAAGAGGTGGTTCAGGTAGCAAGGAAGTTATTTACGACGGGGTAGAGATGGAAATTAATAAAATGAAAATTAAATTTCCGACGCAACTATTCATCAATGGAGAATTCGTTAATTCTGACGGCGGAAAAACAACAGCTATAGTAAATCCCACAGATGAATCTGTTATATGCAAAGTTCAAGCTGCCACAGTATCTGATGTCGACAGGGCTGTTAAAGCTGCTGAGAAGGCCTTCGGAGAAGGAGAATGGTCCAAAATCAGCGCAAGGGAAAGAGGACAGTTATTATTCAAGTTGGCGGATCTAATGGAGCAGCATAAAGAAGAATTAGCCACAATCGAGTCAATAGATTCAGGAGCAGTTTACACTCTAGCACTAAAAACTCACGTGGGCATGTCCATCGAGACATGGAGATATTTCGCCGGCTGGTGTGACAAGATTACAGGTTCAACCATTCCTATTAGCCATGCAAGACCAAATAAAAATCTGACGTTGACAAAAAGAGAACCCATTGGTGTCTGCGGACTGATCACTCCTTGGAATTATCCATTGATGATGTTATCCTGGAAAATGGCCGCTTGCTTGGCAGCTGGCAACACTGTCGTTATGAAACCAGCAGCGGTATGCCCACTCACCGCACTCAAATTCGCTGAGTTGTGCGTGCTAGCCGGCATTCCACCGGGAGTTGTTAATATTGTAACGGGAAGCGGAGCCCTGGCAGGACAAGCCCTTGCTGATCATCCTCGTATCAGGAAGCTTGGATTTACTGGCAGTACTGAAATTGGACAAACTATTATGAAGTCTTGTGCAGCATCAAATTTGAAAAAGGTGTCCTTAGAACTGGGAGGCAAATCTCCATTGATCATCTTTGAAGATTGTGATCTCGATAAAGCAGTTAAAAATGGTATGGCATCAGTATTTTTCAACAAGGGTGAGAATTGCATAGCAGCCGGTCGTTTATTCGTGGAAGAGAAAATACACGACGAGTTTGTTAGACGTGTTGTGGAAGAAACCAAGAAAATGAGCATCGGAGATCCATTAAACAGAGGAACTGCTCATGGCCCACAAAACCACAAAGCCCATATGGATAAACTTATATCGTACGTTGAGACAGGAGTAAAGGAAGGCGCAAAACTGGTTTACGGTGGAAAACGCCTAGATAGACCAGGATACTTCTTCCAACCGACTATATTTACTGATGTCACCGATAATATGGTCATTGCTAAAGAGGAATCTTTTGGACCCATTATGATCATTAGCAAATTTAGCAGCAATAACCTGGATGAAGTGATCCGTCGTGCAAACAACACTGAATATGGGCTAGCGAGCGGCGTATTCACGAAAGACGTTTCACGTGCACTGCGCGTCGCTGAGCGCGTGGAGGCTGGTACCGTCTTCGTGAACACATACAATAAGACCGATGTCGCGGCGCCGTTCGGCGGATTCAAACAGAGTGGTTTTGGAAAGGATCTAGGTCAAGAAGCTCTTAATGAATACCTCAAGACTAAATGTATTACTATAGAATATTGA
>DPOGS206880-PA
MPPVAVPEEPSKKKLRVAIIGQSTFAAEVFKLLQRDGHEVVGVFTVLDKGNREDPLATIAAQNGKPVFKYKTWRVKGQVIPGILEEYKSVNADINVLPFCTQFIPMEVILHPKYQSICYHPSILPRHRGASSINWTLIEGDTTCGLTIFWADDGLDTGPILLQRSFPCTIDDTVDSLYNKYLYPEGIKALAESVNMVANGVAPRIKQTEEGATYDPALFKPETHQIDWSKGGLALHNFIRGLDSSPGATTFIKPQNKDGVDKTSDANIEIKFFGSSLWEAEYETEGDKLFITGLNKPAVVHADGLLITANDGIKLNIQRLKVNGKMINAQNFYKGSENKVSLDLTAEEKQFIEKARDVWKAILRIEIENDTDFFASGAGSMDVVRLVEEIKDISELELQNEDIYMNTTFEDFYNAAILKQRGGSGSKEVIYDGVEMEINKMKIKFPTQLFINGEFVNSDGGKTTAIVNPTDESVICKVQAATVSDVDRAVKAAEKAFGEGEWSKISARERGQLLFKLADLMEQHKEELATIESIDSGAVYTLALKTHVGMSIETWRYFAGWCDKITGSTIPISHARPNKNLTLTKREPIGVCGLITPWNYPLMMLSWKMAACLAAGNTVVMKPAAVCPLTALKFAELCVLAGIPPGVVNIVTGSGALAGQALADHPRIRKLGFTGSTEIGQTIMKSCAASNLKKVSLELGGKSPLIIFEDCDLDKAVKNGMASVFFNKGENCIAAGRLFVEEKIHDEFVRRVVEETKKMSIGDPLNRGTAHGPQNHKAHMDKLISYVETGVKEGAKLVYGGKRLDRPGYFFQPTIFTDVTDNMVIAKEESFGPIMIISKFSSNNLDEVIRRANNTEYGLASGVFTKDVSRALRVAERVEAGTVFVNTYNKTDVAAPFGGFKQSGFGKDLGQEALNEYLKTKCITIEY-