| DPOGS208546 | ||
|---|---|---|
| Transcript | DPOGS208546-TA | 684 bp |
| Protein | DPOGS208546-PA | 227 aa |
| Genomic position | DPSCF300064 + 940871-942733 | |
| RNAseq coverage | 932x (Rank: top 14%) | |
| Annotation | ||||
|---|---|---|---|---|
| Heliconius | HMEL008763 | 9e-133 | 99.56% | |
| Bombyx | BGIBMGA010333-TA | 3e-131 | 98.24% | |
| Drosophila | U2af38-PA | 7e-108 | 96.83% | |
| EBI UniRef50 | UniRef50_Q01081 | 6e-91 | 83.60% | Splicing factor U2AF 35 kDa subunit n=64 Tax=Opisthokonta RepID=U2AF1_HUMAN |
| NCBI RefSeq | XP_001606160.1 | 3e-113 | 83.13% | PREDICTED: similar to U2 snrnp auxiliary factor, small subunit [Nasonia vitripennis] |
| NCBI nr blastp | gi|156543322 | 6e-112 | 83.13% | PREDICTED: splicing factor U2af 38 kDa subunit-like [Nasonia vitripennis] |
| NCBI nr blastx | gi|91089827 | 2e-119 | 92.14% | PREDICTED: similar to AGAP002956-PA [Tribolium castaneum] |
| Group | ||||
|---|---|---|---|---|
| Gene Ontology | GO:0005634 | 4.3e-170 | nucleus | |
| GO:0003723 | 4.3e-170 | RNA binding | ||
| GO:0000166 | 1e-24 | nucleotide binding | ||
| GO:0003676 | 6.1e-22 | nucleic acid binding | ||
| GO:0008270 | 1.6e-07 | zinc ion binding | ||
| KEGG pathway | nvi:100113925 | 9e-113 | ||
| K12836 (U2AF1) | maps-> | Shigellosis | ||
| Spliceosome | ||||
| InterPro domain | [1-227] IPR009145 | 4.3e-170 | U2 auxiliary factor small subunit | |
| [43-148] IPR012677 | 1e-24 | Nucleotide-binding, alpha-beta plait | ||
| [69-146] IPR003954 | 6.1e-22 | RNA recognition motif domain, eukaryote | ||
| [15-38] IPR000571 | 1.6e-07 | Zinc finger, CCCH-type | ||
| [95-143] IPR000504 | 1.4e-06 | RNA recognition motif domain | ||
| Orthology group | MCL15143 | Single-copy universal gene | ||
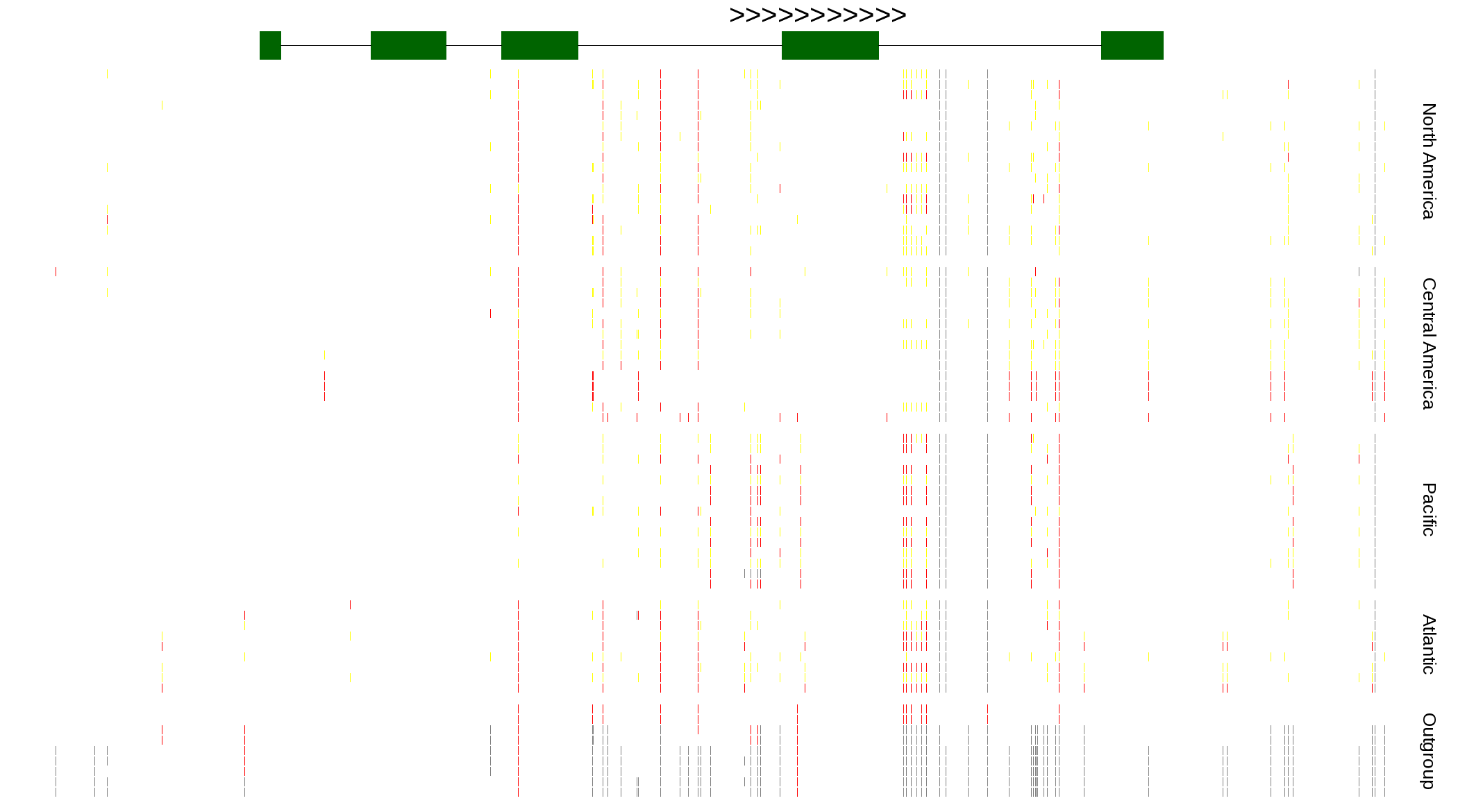
| Genotypes for resequenced monarchs and outgroup Danaus species |
|---|
>DPOGS208546-TA
ATGGCCGAATATTTAGCGGCTATATTTGGTACTGAAAAGGATAAGGTAAATTGCTCATTCTATTTTAAAATAGGAGCTTGTCGACATGGTGATCGATGTTCGAGAATTCATAACAAACCAACTTTTTCGCAAACTGTGTTGCTACAAAATTTATATGTAAATCCACAAAACTCAGCCAAGTCTGCTGATGGCAGTCATTTGGTTGTGGCAAATGTATCGGACGAGGAGATGCAAGAGCACTATGATAACTTTTTTGAAGATGTTTTTGTTGAATGTGAAGATAAATATGGTGAAATTGAGGAAATGAATGTATGTGACAACCTCGGAGATCACTTAGTAGGCAATGTTTATATTAAGTTTCGCCGAGAGGAAGATGCCGAGAAGGCTGTAAATGACCTCAATAACCGCTGGTTTGGAGGCCGGCCTGTTTATGCTGAGTTGTCTCCTGTAACTGACTTCCGTGAAGCTTGCTGTCGTCAGTATGAAATGGGGGAATGTACCAGGAGTGGCTTTTGTAATTTCATGCACTTGAAACCAATTTCAAGAGAACTGAGGAGATACCTGTACGCTCGTCGTAAGGGCGGCCGCCGGTCCAGGTCCAGGTCTCGTGAGCGTCGCCGGCGATCGAGATCGCGCGACCGTCGCCGCGAGCCGCCTCGCAACTCGCGCTCTGGACGGTACTGA
>DPOGS208546-PA
MAEYLAAIFGTEKDKVNCSFYFKIGACRHGDRCSRIHNKPTFSQTVLLQNLYVNPQNSAKSADGSHLVVANVSDEEMQEHYDNFFEDVFVECEDKYGEIEEMNVCDNLGDHLVGNVYIKFRREEDAEKAVNDLNNRWFGGRPVYAELSPVTDFREACCRQYEMGECTRSGFCNFMHLKPISRELRRYLYARRKGGRRSRSRSRERRRRSRSRDRRREPPRNSRSGRY-